
Unleashing the Power of Large Language Models for SEO
Large language models have gained significant attention in recent years due to their ability to generate high-quality text. In particular, these models have been applied to the field of search engine optimization (SEO) in order to improve the ranking of websites and the relevance of search results.
This article summarizes the key aspects of large language models and their impact on SEO.
What are Large Language Models?
Large language models are a class of neural network models that are trained on massive amounts of text data in order to learn the patterns and structures of natural language. These models typically use a combination of recurrent neural networks (RNNs) and long short-term memory (LSTM) units, which are designed to capture long-range dependencies in the input data.
The training process for large language models involves feeding the model a large corpus of text, such as a collection of books or articles. The model then learns to predict the next word in a sequence based on the words that have come before it. This process is repeated many times, with the model gradually improving its predictions and learning to capture the patterns and structures of natural language.
Once the model is trained, it can be applied to a wide range of language tasks, such as text generation, machine translation, and text summarization. For example, a large language model might be used to generate a paragraph of text based on a given topic or prompt, or to translate a sentence from one language to another.
Performance of Large Language Models
One of the key advantages of large language models is their ability to generate high-quality text that is difficult to distinguish from human-written content. This is because these models are trained on a large amount of data, which allows them to capture the nuances and complexities of natural language.
In recent years, large language models have achieved impressive performance on a range of benchmarks and evaluations, including the Turing test, which measures the ability of a model to generate human-like text. For example, in 2019, a large language model developed by OpenAI called GPT-2 achieved a score of 63.4 on the Turing test, which is considered a significant milestone in the field of natural language processing (NLP).
Another measure of the performance of large language models is their ability to generate coherent and coherent text. In this regard, large language models have also demonstrated impressive performance. For example, a model called GPT-3, which was developed by OpenAI in 2020, was able to generate text that was rated as being more coherent and coherent than text written by humans on the same topic.
Overall, the performance of large language models on a range of benchmarks and evaluations suggests that these models have the potential to generate high-quality text that is difficult to distinguish from human-written content.
How are Large Language Models Trained and Tested?
Training and testing large language models is a complex and highly technical process that involves a combination of sophisticated algorithms, vast amounts of data, and significant computing power.
At a high level, large language models are trained by feeding them vast amounts of text data, which they use to learn about the structure and patterns of language. This can be done using a variety of algorithms and techniques, including unsupervised learning, where the model is left to explore the data on its own and make inferences, or supervised learning, where the model is provided with explicit examples of correct language use.
Once the model has been trained, it can then be tested to evaluate its performance and accuracy. This is typically done by providing the model with a set of test data that it has not seen before, and comparing its outputs to known correct answers or benchmarks. This allows researchers and developers to assess the model's ability to understand and generate natural language, and to identify areas where it may be lacking or need further improvement.
There are many different approaches and techniques that can be used in the training and testing of large language models, and the specific methodologies employed will depend on the specific goals and objectives of the model, as well as the available resources and technology.
Some common techniques include:
- Cross-validation: where the model is trained and tested on different subsets of the data, to ensure that it generalizes well and is not overfitting to specific examples.
- Fine-tuning: where the model is pre-trained on a large dataset and then fine-tuned on a smaller, more specialized dataset, to improve its performance on specific tasks or domains.
- Transfer learning: where the model is trained on one task and then applied to another related task, leveraging its pre-existing knowledge and expertise to improve performance.
In addition to these technical considerations, there are also important ethical and societal issues surrounding the training and testing of large language models. For example, the data used to train the model must be carefully selected and curated to avoid introducing biases or stereotypes that could affect the model's performance and behavior. Additionally, the testing of large language models must be done in a transparent and accountable manner, to ensure that the results are reliable and fair.
Overall, the training and testing of large language models is a complex and multifaceted process that requires a deep understanding of natural language processing, machine learning, and data science, as well as a strong commitment to ethical and responsible development practices.
What are Some Common Applications of Large Language Models?
One common application of large language models is natural language processing (NLP). NLP is a field of artificial intelligence that focuses on enabling machines to understand, interpret, and generate human language. Large language models are particularly well-suited to NLP tasks because they can process and analyze large amounts of text data to extract meaning and make predictions.
One example of an NLP task that large language models can perform is text classification. This involves training a model on a large dataset of labeled texts, where each text has been manually assigned a specific category or label. The model then learns to predict the correct label for new, unseen texts. This can be useful for tasks such as sentiment analysis, where the goal is to determine whether a given piece of text is positive, negative, or neutral in tone.
Another example of an NLP task that large language models can perform is machine translation. This involves training a model to translate text from one language to another. Large language models are particularly well-suited to this task because they can process and analyze large amounts of bilingual text data to learn the relationships between words and phrases in different languages. This allows the model to generate high-quality translations that are accurate and fluent.
Large language models are also commonly used for text summarization, which involves generating a condensed version of a text that retains its most important information. This can be useful for tasks such as news aggregation, where the goal is to provide a brief overview of multiple articles on the same topic. Large language models are able to analyze the content of a text and extract the most relevant and salient information to generate a concise summary.
Another potential application of large language models is dialogue systems, which allow users to have natural language conversations with machines. Large language models can be used to generate responses that are appropriate, coherent, and natural-sounding in a given context. This can be useful for tasks such as customer service, where the goal is to provide helpful and accurate information to users in a conversational manner.
Finally, large language models are used in modern search engines for query expansion. This allows the search engine to perform a better search than the user, who may not know how to properly search for what they are actually looking for.
Overall, large language models have a wide range of potential applications in natural language processing and other fields. They are able to process and analyze large amounts of text data to extract meaning and make predictions, which makes them powerful tools for tasks such as text classification, machine translation, text summarization, and dialogue systems. As the field of artificial intelligence for SEO continues to advance, it is likely that we will see even more creative and exciting applications of large language models in the future.
How Do Large Language Models Compare to Other Natural Language Processing Techniques?
Large language models, such as GPT-3, GPT-4, BERT, Sentence-BERT, and Google's AI Overviews have become increasingly popular in the field of natural language processing. These models are trained on large datasets and use deep learning techniques to process and generate human-like language.
One way in which large language models differ from other natural language processing techniques is in their ability to generate human-like language. Traditional techniques often require a strict set of rules or pre-defined responses, but large language models are able to generate more flexible and varied responses. This ability makes them particularly useful for tasks such as language translation, text summarization, and text generation.
Another key difference is the sheer size of large language models. These models are trained on massive datasets and can have billions of parameters, which allows them to capture a wide range of linguistic patterns and nuances. This allows them to perform well on a variety of language tasks, including tasks that require understanding of context or broader knowledge about the world.
Despite their impressive abilities, large language models are not without their limitations. One major limitation is the amount of computational power and resources required to train and run these models. This can make them impractical for some applications and can also raise concerns about their environmental impact. Additionally, large language models are still limited by the quality and biases of the data they are trained on. This can lead to errors or unfair treatment of certain groups in certain applications.
Overall, large language models represent an exciting development in the field of natural language processing. While they have their limitations, they have the potential to greatly improve our ability to process and generate human-like language. As these models continue to evolve and improve, we can expect to see them playing a larger role in a wide range of applications.
Are there Ethical Considerations Surrounding the Use of Large Language Models?
The use of large language models has sparked a great deal of debate and discussion in the field of natural language processing and artificial intelligence. While these models have shown impressive performance in a variety of tasks, they have also raised important ethical considerations that must be addressed.
One of the key ethical concerns surrounding large language models is the issue of bias. Because these models are trained on vast amounts of data, they can sometimes incorporate biases that exist in the data. For example, if a large language model is trained on a dataset that contains a disproportionate number of examples written by white males, the model may produce biased outputs when applied to other demographics. This can have serious consequences, such as perpetuating harmful stereotypes and discrimination.
Another ethical concern is the issue of privacy. Because large language models require vast amounts of data to be effective, they often rely on data collected from individuals without their knowledge or consent. This raises questions about the ethical implications of using personal data in this way, and whether individuals should have the right to opt out of having their data used in this manner.
Another potential issue is the lack of accountability and transparency in the development and use of large language models. Because these models are so complex, it can be difficult for outsiders to understand how they work and what factors might be influencing their outputs. This lack of transparency can make it difficult to hold developers and users accountable for any negative consequences of using large language models.
Furthermore, there are concerns about the potential for large language models to be used for nefarious purposes. For example, these models could be used to generate fake news or other forms of disinformation at a scale that is difficult to detect or combat. This could have serious consequences for democracy and social stability.
Overall, the use of large language models presents both exciting opportunities and important ethical considerations. It is important for researchers, developers, and policymakers to carefully consider these issues and take steps to address them in order to ensure that these powerful tools are used responsibly and for the benefit of society as a whole.
How Large Language Models can be Applied to SEO
In the context of SEO, large language models can be used to generate high-quality content that is optimized for search engine rankings. By understanding the language and content preferences of search engines, these models can produce text that is more likely to rank well and attract organic traffic.
One way in which large language models can be applied to SEO is by generating text that is optimized for specific keywords and phrases. By training the model on a large corpus of text that includes the target keywords and phrases, the model can learn to generate text that is more likely to rank well for those keywords and phrases.
For example, a large language model could be trained on a corpus of text that includes the keyword "dog training," with the goal of generating text that is optimized for that keyword. The model might learn to use common phrases and terms associated with dog training, such as "positive reinforcement" and "clicker training," in order to create text that is more likely to rank well for that keyword.
Another way in which large language models can be applied to SEO is by generating text that is optimized for specific topics or categories. By training the model on a large corpus of text that covers a specific topic or category, the model can learn to generate text that is relevant and informative for that topic or category.
For example, a large language model could be trained on a corpus of text that covers the topic of health and wellness, with the goal of generating text that is relevant and informative for that topic. The model might learn to use common terms and phrases associated with health and wellness, such as "exercise" and "nutrition," in order to create text that is informative and relevant for that topic.
In addition to generating text that is optimized for keywords and topics, large language models can also be used to improve the relevance of search results. By extracting summaries and keywords that accurately represent the content of a website, these models can help search engines to provide more relevant and useful search results to users.
For example, a large language model could be trained on a corpus of text that includes summaries and keywords for a large number of websites. The model could then be used to generate summaries and keywords for a new website, based on the content of that website.
This would help search engines to provide more relevant and useful search results to users, as the summaries and keywords generated by the model would accurately represent the content of the website.
Future Prospects of Large Language Models in SEO
Despite the challenges and limitations discussed above, large language models are likely to continue to play an important role in the field of SEO. As these models become more advanced and more efficient, it is likely that they will be used in an even wider range of applications, including the generation of high-quality content that is optimized for search engine rankings.
Additionally, as the performance of large language models continues to improve, it is likely that these models will become increasingly capable of generating text that is difficult to distinguish from human-written content. This could lead to the development of new tools and platforms that use large language models to generate content on a large scale, potentially transforming the way that content is produced and distributed on the web.
Overall, the future prospects of large language models in SEO are bright, and it is likely that these models will continue to play a key role in the field in the coming years. As these models become more advanced and more efficient, they will enable organizations to generate high-quality content that is optimized for search engine rankings, and they will help to improve the relevance and usefulness of search results for users.
the future of LLM AND gpt-3
Challenges and Limitations of Large Language Models in SEO
While large language models have the potential to greatly improve the effectiveness of SEO strategies, there are also a number of challenges and limitations that need to be considered.
One challenge is the cost and complexity of training large language models. These models require a massive amount of data and computational resources in order to be trained effectively, which can be prohibitively expensive for many organizations. Additionally, the training process for large language models can be complex and time-consuming, requiring specialized expertise and knowledge.
Another challenge is the quality of the natural language text generated by large language models. While these models are capable of generating high-quality text, there are also instances where the text generated by the model may be nonsensical or poorly written. This can be a problem in the context of SEO, as search engines may penalize websites that contain low-quality or spammy content.
Additionally, there are ethical and legal concerns surrounding the use of large language models in SEO. For example, there are concerns that these models could be used to generate content that is misleading or deceptive, or to manipulate search engine rankings in unfair or unethical ways. There are also concerns about the potential for these models to be used to generate large amounts of automated content, which could impact the quality and diversity of content on the web.
large language models in market brew
Large Language Models in Market Brew
Market Brew has a number of Large Language Model technologies embedded inside it, which work in concert with its Knowledge Graph and the SPARQL language.
This allows the platform to use large language models to annotate all content and identify, extract, and disambiguate named entities.
By using this technology to build automated topic clusters of content, Market Brew is able to find deep relationships within its content graph, inferring in the same way that modern search engines like Google do.
One of the standout features of Market Brew is its Spotlight, which uses LLM technologies to extract each page's Related Entities, Expert Topics, and more.
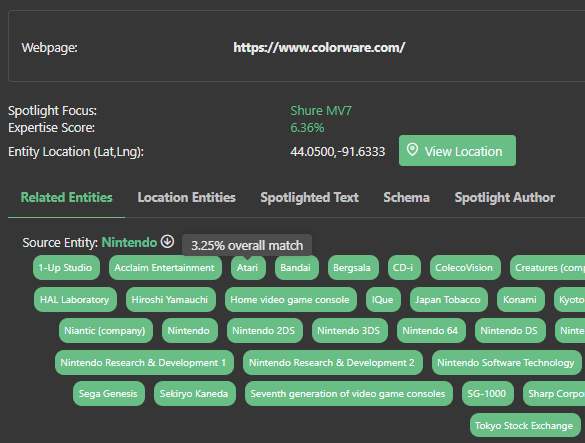
Market Brew takes full advantage of the power of large language models to provide users with highly relevant and accurate search results.
You May Also Like:
History
Evolution of the PageRank Algorithm
Guides & Videos
Neural Networks & SEO: A Perfect Match
Guides & Videos
Others
How Google’s AI Overview and LLM’s Work
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.