
Natural Language Processing's Role in SEO and Search Engines
Natural language processing (NLP) is a field of artificial intelligence that focuses on the interaction between computers and human language. In the context of search engine optimization (SEO) and search engines, NLP plays a crucial role in helping search engines understand and interpret user queries, improving the accuracy and relevance of search results.
This paper explores the basics of NLP, its applications in SEO and search engines, and the role of GPT-3 and Large Language Models (LLMs) in advancing the field.
Introduction to Natural Language Processing (NLP)
Natural language processing (NLP) is a field of artificial intelligence (AI) that focuses on the interaction between computers and human language. It involves the use of algorithms and models to analyze and understand human language in order to enable better communication between computers and humans.
In recent years, NLP has become increasingly important in various applications, including search engine optimization (SEO) and search engines.
NLP is commonly used in named entity recognition, where search engines use the technology to extract and disambiguate entities that are tied to a knowledge graph.
Another technology that fits into NLP is the use of large language models (LLMs). These models use deep learning algorithms to process and understand large amounts of text data, allowing for more accurate and sophisticated language processing.
One example of an LLM is GPT-3 (Generative Pretrained Transformer-3), which was developed by OpenAI. GPT-3 has the ability to generate human-like text and has been used in a variety of applications, including language translation and language generation.
In the context of SEO and search engines, GPT-3 and other LLMs have the potential to improve search results by providing more accurate and relevant information. However, there are also potential challenges and implications to consider, such as the potential for bias and the need for ethical considerations in the use of these technologies.
Overall, NLP, GPT-3, and LLMs are important technologies in the context of SEO and search engines, and their continued development and use will likely have significant implications for the future of these industries.
The Role of Natural Language Processing in Query Parsers
The Query Parsers and Natural Language Processing (NLP) are important tools in the world of search engines. They are responsible for interpreting and analyzing the queries entered by users in order to provide relevant and accurate results.
Query Parsers are the first step in the process of search engine querying. They are designed to take a user's query and break it down into smaller, more manageable pieces. This involves identifying the different components of the query, such as keywords, phrases, and operators, and assigning each one a specific role in the search via text classification.
Once the query has been parsed, the search engine's NLP algorithms come into play. These algorithms use sophisticated techniques to analyze the query and understand its meaning and user search intent. This involves identifying the main concepts and ideas contained within the query, and determining how they relate to each other.
One of the key tasks of NLP algorithms is to determine the meaning and context of words and phrases in a query. This is done through a process known as word sense disambiguation, which involves examining the surrounding words and the context in which the query was entered to determine the intended meaning of each word.
Another important aspect of NLP is the ability to understand the relationships between different concepts and ideas in a query. This is done through a process known as concept extraction, which involves identifying the key concepts and ideas contained within the query and determining how they relate to each other.
Once the query has been fully analyzed, the search engine's algorithms can use this information to provide relevant and accurate results. This involves ranking the results based on their relevance to the query, and presenting them to the user in a way that is easy to understand and navigate.
Overall, the Query Parsers and NLP algorithms play a crucial role in the functioning of search engines. They enable users to enter complex queries and receive relevant and accurate results, and are constantly evolving to provide even better search experiences.
The Rise of Large Language Models in Natural Language Processing
Large language models (LLMs) are a type of natural language processing (NLP) tool that uses massive amounts of data and computational power to learn and understand natural language. These models are trained on large datasets, often consisting of millions or billions of words, and use complex algorithms to recognize patterns and relationships in the data.
LLMs are a key component of many modern NLP systems, such as machine translation, speech recognition, and text summarization. They are particularly useful for tasks that require a high degree of language understanding, such as understanding the context and meaning of words and sentences.
One of the most well-known LLMs is the Transformer model, developed by Google in 2017. This model uses a deep learning algorithm called an attention mechanism to process large amounts of data and make predictions about the next word in a sentence. This allows the model to capture complex relationships between words and improve the accuracy of its predictions.
Another popular LLM is BERT (Bidirectional Encoder Representations from Transformers), developed by Google in 2018. BERT is a type of transformer model that uses a unique training technique called "masking" to better understand the context and meaning of words in a sentence. A more advanced version of this, Sentence-BERT, takes this approach and puts the entire sentence into context. This has led to significant improvements in the accuracy of NLP tasks such as sentiment analysis and question answering, and can be now seen in Google's Multitask Unified Model (MUM).
LLMs have many potential applications, including improving the accuracy of machine translation and speech recognition systems, enhancing the performance of search engines, and enabling more intelligent chatbots and virtual assistants. However, these models also raise concerns about data privacy and bias, as they are trained on large amounts of data that may contain sensitive information or be biased towards certain groups.
One way to address these concerns is to use LLMs in combination with other NLP techniques, such as rule-based expert systems or human-in-the-loop methods. This can help to ensure that the models are more accurate and fair, and reduce the risk of negative consequences from their use.
Overall, LLMs are a powerful tool for NLP, but their use must be carefully considered in order to maximize their potential benefits and minimize potential drawbacks. As the field of NLP continues to advance, we can expect to see even more sophisticated LLMs and applications in the future.
Revolutionizing Search: The Power of GPT-3 in Modern Search Engine Technology
GPT-3, or Generative Pretrained Transformer 3, is a state-of-the-art natural language processing (NLP) model developed by OpenAI. It has 175 billion parameters, making it the largest language model to date. GPT-3 has been shown to be capable of generating human-like text, performing language translation, and even writing code.
One potential application of GPT-3 is in search engines. Currently, search engines rely on keyword matching to retrieve relevant results for a query. However, this method has limitations, such as the inability to understand the context and intent behind a query.
GPT-3, with its advanced language understanding capabilities, could potentially improve the accuracy and relevance of search results. It could analyze the context and user search intent behind a query, and generate more personalized and relevant results. For example, if a user searches for "Italian restaurants near me," GPT-3 could understand that the user is looking for Italian restaurants in their current location, and provide results accordingly.
In addition, GPT-3 could also enhance search engines' ability to understand natural language queries. Currently, search engines require users to input specific keywords in a specific order to retrieve relevant results. With GPT-3, search engines could understand more complex and conversational queries, such as "I'm looking for a good Italian restaurant with outdoor seating and a kids' menu."
Furthermore, GPT-3 could also improve search engine performance by generating summaries for long documents, such as articles and research papers. This could make it easier for users to quickly find the information they are looking for, without having to read through the entire document.
However, there are also potential drawbacks to using GPT-3 in search engines. One concern is the potential for bias in the generated results. GPT-3 is trained on large amounts of text data, and therefore may reflect the biases present in that data. This could result in unfair or discriminatory results being generated by the search engine.
Another concern is the potential for misuse of GPT-3 by malicious actors. GPT-3's ability to generate human-like text could be exploited for spamming or disinformation campaigns. Search engines would need to implement safeguards to prevent such misuse.
Overall, GPT-3 has the potential to improve the accuracy and relevance of search engine results. However, careful consideration must be given to addressing potential biases and misuses of the technology.
Natural Language Processing (NLP) in SEO and Search Engines
Large language models (LLMs) and GPT-3 have the potential to revolutionize the field of search engine optimization (SEO). LLMs are a type of artificial intelligence (AI) technology that uses deep learning algorithms to process and understand large amounts of text data. GPT-3 is a specific type of LLM developed by the AI research company OpenAI, which has been trained on a massive amount of text data from various sources.
One potential use of LLMs and GPT-3 in SEO is for keyword research and optimization. Traditionally, keyword research involves manually analyzing search data and determining which keywords and phrases are most commonly used by users to find specific types of content. LLMs and GPT-3, however, can automate this process by analyzing large amounts of text data and identifying common patterns and trends in language use. This can help SEO professionals identify the most effective keywords and phrases to use in their content, improving its visibility and ranking in search engine results.
Another potential use of LLMs and GPT-3 in SEO is for content creation and optimization. LLMs and GPT-3 can be used to generate high-quality, relevant content that is optimized for specific keywords and phrases. This can be particularly useful for SEO professionals who need to create a large amount of content quickly, or who lack the time or resources to write content themselves. LLMs and GPT-3 can also be used to optimize existing content by identifying and correcting errors or inconsistencies in language use, improving its readability and relevance to search queries.
LLMs and GPT-3 can also be used for link building and analysis. Link building is a crucial part of SEO, as it involves creating and acquiring links from other websites to improve a website's visibility and ranking in search engine results. LLMs and GPT-3 can be used to analyze large amounts of text data to identify relevant and high-quality websites that are worth linking to. This can help SEO professionals identify opportunities for link building and improve the overall quality of their website's link profile.
Finally, LLMs and GPT-3 can be used for analysis and reporting on SEO performance. LLMs and GPT-3 can be used to analyze large amounts of data from various sources, such as search engine results, website traffic, and user behavior data. This can help SEO professionals identify trends and patterns in their performance and make data-driven decisions to improve their SEO strategies.
Overall, LLMs and GPT-3 have the potential to greatly enhance the effectiveness of SEO by automating and improving various processes and tasks. By leveraging the power of deep learning algorithms, LLMs and GPT-3 can help SEO professionals save time, improve the quality of their work, and achieve better results for their clients.
Challenges and Limitations of LLMs and GPT-3
Large language models (LLMs) have become increasingly popular in recent years, thanks to their ability to generate human-like text and provide valuable insights for natural language processing tasks. Despite their impressive capabilities, LLMs come with a number of challenges and limitations that need to be considered when using them for various applications.
One of the main challenges of LLMs is their sheer size and computational power requirements. LLMs like GPT-3 consist of millions of parameters, making them extremely expensive to train and run. This not only limits their accessibility to only large organizations with the resources to handle them, but also poses a challenge in terms of scalability and generalizability.
Another challenge is the potential for bias in LLMs. LLMs are trained on large amounts of text data, which may include biases present in the source material. This can lead to biased language generation and decision-making by the model, which can be harmful in certain contexts.
LLMs also struggle with understanding and handling context and context shifts. While they may be able to generate coherent text within a given context, they may struggle to understand and adapt to changes in context within a conversation or document. This can lead to confusion or incoherent text generation.
Furthermore, LLMs are not capable of handling open-ended or unstructured tasks. They rely on pre-defined parameters and objectives, and are not able to think creatively or generate novel ideas on their own. This limits their potential applications and usefulness in certain contexts.
Additionally, LLMs are not capable of understanding the emotional or affective aspects of language. They are unable to interpret or generate emotional responses, which can be crucial in certain applications such as customer service or emotional intelligence tasks.
In conclusion, while LLMs like GPT-3 have impressive capabilities, they come with a number of challenges and limitations that need to be carefully considered when using them for various applications.
These challenges include their size and computational power requirements, potential for bias, difficulty in handling context and context shifts, lack of ability to handle open-ended tasks, and inability to understand emotional aspects of language.
It is important to consider these limitations and carefully evaluate the potential applications and usefulness of LLMs before using them for various tasks.
market brew natural language processing
Natural Language Processing in Market Brew
Market Brew has a number of Natural Language Processing (NLP) technologies embedded inside it.
Using NLP technologies to annotate all content via part-of-speech tagging, Market Brew is able to identify, extract, and disambiguate named entities, like “Johnny Depp” or “Pirates of the Caribbean”, and use this information to build automated topic clusters of content, for each page in the search engine model.
Using Market Brew's Knowledge Graph and the SPARQL language, Market Brew is able to find deep relationships within content of each of the named entities in its content graph, and use this to infer the same way a modern search engine like Google does.
Market Brew's Spotlight is one feature in particular that uses the NLP technologies. It is able to extract each page's Related Entities, Expert Topics and more.
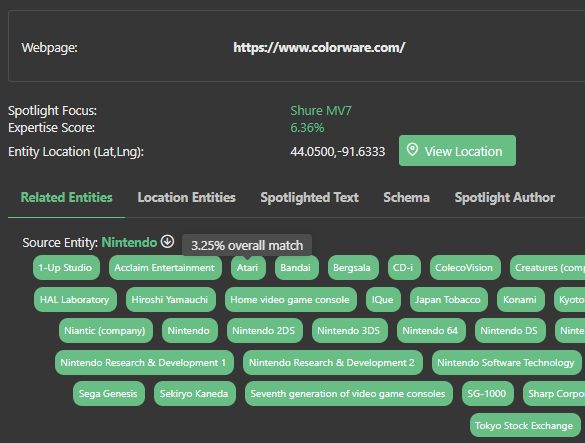
Market Brew's Query Parser can then use these concepts and inject them into queries to infer searches about related entities or concepts, the same way Google does.
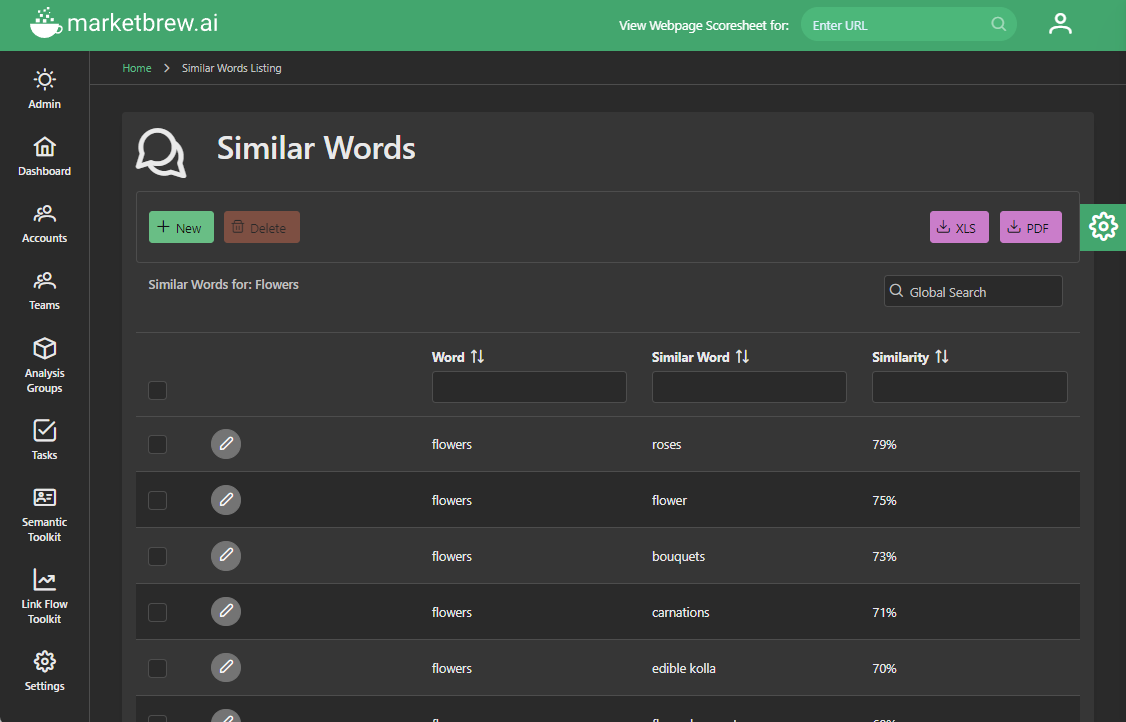
Market Brew contains the most advanced NLP technology that enables users to perform advanced Entity SEO and utilize the latest that NLP has to offer.
You May Also Like:
Others
The Real Lever of AI Persuasion Isn’t Intelligence. It’s Information.
Guides & Videos
Optimizing For Entity SEO
Guides & Videos
Complete Guide to Product Listing Optimization
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.