
The Impact Of BERT On Search Engine Ranking Factors
Google's BERT update has made significant changes to the way search results are displayed, improving natural language processing and providing more relevant results for users.
This article will explore the impact of BERT on search results, the benefits it offers users, and how it has affected SEO and search engine ranking factors.
Additionally, we will discuss the challenges of implementing BERT and whether it will continue to evolve and improve in the future.
In October 2019, Google introduced a major update to its search algorithm called BERT (Bidirectional Encoder Representations from Transformers).
This update has had a significant impact on the way search results are displayed and has made important improvements to natural language processing.
In this article, we will delve into the details of BERT and explore how it has affected search results, user experience, and the SEO industry. We will also discuss the challenges of implementing BERT and consider whether it will continue to evolve and improve in the future.
What Is Google's BERT Update?
Google's BERT update is a natural language processing (NLP) model developed by Google to better understand the meaning and context of words in search queries.
The update was first introduced in October 2019 and has since had a significant impact on the way Google processes and ranks search results.
BERT stands for "Bidirectional Encoder Representations from Transformers." It is a type of transformer-based model that uses attention mechanisms to understand the relationships between words in a sentence. The model is trained on a large dataset of text, allowing it to accurately predict the context and meaning of words based on their position and relationship to other words in a sentence.
One of the key features of BERT is its ability to understand the context of a word in relation to the words that come before and after it. In the past, Google's search algorithms were primarily focused on matching keywords in a search query to the content of a webpage. However, this approach was often limited in its ability to understand the context and meaning of words, leading to less relevant search results.
With the BERT update, Google is able to better understand the meaning and context of words in a search query, resulting in more relevant and accurate search results. This is particularly important for long-tail and complex queries, where the meaning and context of words can be crucial in determining the most relevant search results.
In addition to improving search results for complex and long-tail queries, the BERT update also has the potential to impact the way Google processes and ranks webpages. By better understanding the context and meaning of words on a webpage, Google can more accurately evaluate the relevance and quality of the content, leading to improved rankings for high-quality pages and potentially lower rankings for low-quality pages.
The BERT update has received widespread attention in the SEO (Search Engine Optimization) community, as it has the potential to significantly impact the way websites are ranked by Google. While it is still too early to fully understand the long-term implications of the update, it is clear that BERT represents a major step forward in Google's efforts to improve the accuracy and relevance of its search results.
Overall, the BERT update is a significant development in the field of natural language processing and search engine optimization. It represents a major shift in the way Google processes and ranks search results, and has the potential to significantly improve the quality and relevance of search results for users.
How Does BERT Affect Search Results?
BERT, or Bidirectional Encoder Representations from Transformers, is a machine learning model developed by Google that has had a significant impact on the field of natural language processing (NLP).
BERT is able to understand the context and meaning of words in a sentence, allowing it to accurately process and understand natural language inputs.
One of the main ways that BERT affects search results is through its ability to understand the context and meaning of words in a query.
Prior to BERT, search algorithms relied on matching keywords in a query to the content of web pages. However, this often resulted in irrelevant or inaccurate search results, as the algorithms were not able to understand the context in which the keywords were being used.
For example, if a user searched for "apple store," the algorithm would simply return results that contained the keywords "apple" and "store," regardless of whether the query was related to the tech company Apple or a physical storefront selling apples. BERT, on the other hand, is able to understand that in this case, the user is likely looking for information about the tech company, rather than a store selling fruit.
In addition to improving the accuracy of search results, BERT also allows for more natural and intuitive searches. With BERT, users can use more complex and nuanced queries, as the model is able to understand the meaning and context of their words. This allows users to get more relevant and specific search results, as they can more easily express their needs and interests in their queries.
One of the main ways that BERT has been implemented in search is through its use in Google's search algorithm, known as BERT Ranking. This algorithm uses BERT to better understand the context and meaning of words in a query, allowing it to return more relevant and accurate search results.
BERT has also been used to improve the performance of voice assistants, such as Google Assistant and Amazon's Alexa. By understanding the context and meaning of words, these assistants are able to more accurately interpret and respond to voice commands, leading to a more seamless and natural user experience.
In summary, BERT has had a significant impact on search results by allowing algorithms to better understand the context and meaning of words in a query. This has resulted in more accurate and relevant search results, as well as a more natural and intuitive search experience for users.
What Are The Benefits Of BERT For Users?
BERT, or Bidirectional Encoder Representations from Transformers, is a natural language processing (NLP) model developed by Google in 2018. It has quickly become one of the most popular and effective NLP models in use today, and has been applied to a wide range of tasks including machine translation, question answering, and text classification.
One of the key benefits of BERT for users is its ability to understand context and meaning in natural language.
Unlike many traditional NLP models, which only process text in a linear fashion, BERT is able to analyze the relationships between words and their meanings within the context of the entire sentence or paragraph. This allows it to better understand the intended meaning of a text and provide more accurate and nuanced responses.
Another benefit of BERT is its ability to handle large amounts of data. The model is trained on a massive dataset consisting of over 3 billion words, which allows it to learn a wide range of linguistic patterns and understand complex language structures. This allows it to provide more accurate and reliable results when processing large amounts of text.
One of the most notable applications of BERT is in machine translation. The model is able to accurately translate text from one language to another, with a particular focus on preserving the meaning and context of the original text. This can be especially useful for organizations that need to translate large amounts of text, such as government agencies or multinational corporations.
BERT is also useful for question answering tasks, as it is able to accurately identify the relevant information in a text and provide a concise and accurate response. This can be especially useful for businesses that rely on customer support or frequently receive questions from customers, as it allows them to quickly and accurately respond to inquiries.
In addition to its practical applications, BERT has also contributed to the advancement of NLP research. The model's ability to understand context and meaning in natural language has opened up new possibilities for researchers to explore and improve upon. For example, BERT has been used to create new language models that are able to generate human-like text, which could potentially be used in a variety of applications such as chatbots or automated content generation.
Overall, BERT has numerous benefits for users, including its ability to understand context and meaning in natural language, handle large amounts of data, accurately translate text, and assist with question answering tasks. Its contributions to NLP research have also opened up new possibilities for the development of language models and other NLP technologies. As BERT continues to be refined and improved upon, it is likely to become an increasingly important tool for a wide range of industries and applications.
How Does BERT Improve Natural Language Processing?
BERT, or Bidirectional Encoder Representations from Transformers, is a natural language processing (NLP) model that has significantly improved the ability of computers to understand and process human language. BERT was developed by Google researchers in 2018 and has since become one of the most widely used NLP models in the field.
One of the main ways that BERT improves NLP is through its use of bidirectional context.
Previous NLP models often only considered the context of a word or phrase within a single sentence or small group of sentences. BERT, on the other hand, considers the context of a word or phrase within the entire document or paragraph. This allows BERT to better understand the meaning of words and phrases within the context of the larger text.
Another key aspect of BERT is its use of attention mechanisms. These mechanisms allow the model to focus on specific words or phrases within a text and consider their importance in relation to other words or phrases. This allows BERT to understand the relationships between different words and phrases within a text, which is essential for accurate language processing.
BERT also uses a transformer architecture, which allows it to process a large amount of data in parallel. This makes BERT much faster and more efficient than previous NLP models, which often relied on sequential processing. This allows BERT to process large amounts of text quickly and accurately, making it ideal for tasks such as language translation and language summarization.
One of the main applications of BERT is in the field of language translation. Traditional language translation models often rely on statistical machine translation, which involves training a model on a large dataset of human-translated texts. However, these models can be limited by the quality and diversity of the training data. BERT, on the other hand, is able to learn the patterns and relationships between different languages by analyzing large amounts of text data. This allows it to produce more accurate and natural-sounding translations compared to traditional models.
BERT has also been used to improve the performance of language generation tasks, such as text summarization and question answering. In these tasks, BERT is able to understand the meaning and context of a text and generate a summary or answer that accurately reflects the original text. This has the potential to revolutionize the way we access and consume information, making it easier to understand and process large amounts of text.
In addition to its applications in language translation and language generation, BERT has also been used to improve the performance of language classification tasks, such as sentiment analysis and spam detection. By understanding the meaning and context of text, BERT is able to accurately classify the sentiment or intent of a text, which can be useful in a variety of applications.
Overall, BERT has greatly improved the ability of computers to understand and process human language. Its use of bidirectional context, attention mechanisms, and transformer architecture allows it to accurately understand the meaning and context of text, making it ideal for a wide range of natural language processing tasks. Its impact on the field of NLP has been significant, and it is likely to continue to shape the future of language processing technology.
What Types Of Queries Does BERT Benefit Most?
BERT, which stands for "Bidirectional Encoder Representations from Transformers," is a natural language processing (NLP) model developed by Google that has revolutionized the way computers understand and process human language. It is particularly useful for tasks such as question answering, translation, and sentiment analysis.
However, there are certain types of queries that BERT benefits most.
One type of query that BERT excels at is long-form queries with multiple clauses or words. This is because BERT is able to take into account the context and relationships between words in a sentence, rather than just focusing on individual words in isolation. For example, consider the query "What are the best restaurants near the Eiffel Tower in Paris that serve vegan food?" BERT is able to understand the context and relationships between the various words and clauses in this query, such as the location, type of food, and specific landmarks mentioned, and provide accurate and relevant results.
Another type of query that BERT is particularly effective at is those that involve natural language processing tasks such as question answering and translation. BERT is able to understand the nuances and complexities of human language, allowing it to accurately answer questions or translate text in a way that is similar to how a human would. This is especially useful for tasks such as customer service, where the ability to accurately and efficiently understand and respond to customer inquiries is crucial.
BERT also excels at queries that involve understanding the sentiment or emotion behind a statement. For example, consider the query "Is this product worth purchasing?" BERT is able to understand the underlying sentiment behind this question, and provide results that are relevant to whether or not the product is considered a good value or not. This can be extremely useful for tasks such as product reviews or customer feedback, where understanding the overall sentiment of a statement is crucial for providing accurate and relevant results.
In addition to these types of queries, BERT is also effective at handling queries that involve complex language or concepts. This is because BERT is able to understand the relationships between words and concepts, allowing it to accurately process queries that may be difficult for other NLP models to understand. For example, consider the query "What is the difference between relativistic mass and invariant mass?" BERT is able to understand the complex concepts involved in this query and provide accurate and relevant results.
Overall, BERT is a powerful NLP model that is particularly effective at handling long-form queries with multiple clauses, natural language processing tasks such as question answering and translation, queries involving sentiment analysis, and queries involving complex language or concepts. Its ability to understand the context and relationships between words and concepts allows it to provide accurate and relevant results for a wide variety of queries.
How Does BERT Affect SEO?
BERT, or Bidirectional Encoder Representations from Transformers, is a natural language processing (NLP) technique developed by Google in 2019.
It has significantly impacted search engine optimization (SEO) by improving the way Google understands and processes language in search queries and online content.
Before BERT, Google primarily relied on keyword matching to determine the relevance of a webpage to a given search query. This meant that Google would look for specific keywords in the query and the webpage to determine how well they aligned. However, this often led to irrelevant or misleading search results, as it didn't take into account the context and meaning behind the words.
BERT allows Google to better understand the context and meaning behind words and phrases in search queries and online content. It does this by using a machine learning algorithm that analyzes the relationships between words in a sentence, rather than just the individual words themselves. This allows Google to better understand the intent behind a search query and provide more accurate and relevant search results.
For SEO, this means that it's no longer enough to simply stuff keywords into your content and expect to rank well in search results. Instead, you need to focus on creating high-quality, well-written content that accurately and clearly communicates your message. This means using natural language and avoiding keyword stuffing or other tactics that might mislead or deceive readers.
One way that BERT has affected SEO is by prioritizing long-tail keywords. These are more specific, detailed phrases that are more likely to reflect the intent behind a search query. For example, "how to fix a leaking faucet" is a long-tail keyword that might be more relevant to a search query than just the keyword "faucet." By prioritizing long-tail keywords, BERT allows
Google to better understand the specific needs and interests of searchers and provide more targeted, relevant results.
Another way that BERT has impacted SEO is by making it more important to focus on the user experience. Google wants to provide the best possible search experience for its users, so it rewards websites that provide high-quality, helpful content. This means that in addition to optimizing for keywords and search rankings, you should also focus on creating a great user experience for your visitors. This includes things like fast loading times, easy navigation, and mobile-friendliness.
Finally, BERT has also made it more important to optimize for featured snippets. These are the brief summaries that appear at the top of search results and are designed to answer a user's question or provide additional information. By optimizing for featured snippets, you can increase your chances of appearing in these top positions and getting more traffic to your website.
In conclusion, BERT has significantly affected SEO by improving the way Google understands and processes language in search queries and online content. This has made it more important to focus on creating high-quality, well-written content that accurately and clearly communicates your message, as well as optimizing for long-tail keywords, user experience, and featured snippets. By following these best practices, you can improve your search rankings and drive more traffic to your website.
What Are The Challenges Of Implementing BERT?
BERT, or Bidirectional Encoder Representations from Transformers, is a revolutionary natural language processing (NLP) model developed by Google in 2018.
It has been widely hailed as a major breakthrough in the field, as it has significantly improved the performance of NLP tasks such as language translation, text classification, and sentiment analysis.
However, implementing BERT is not without its challenges.
Here are some of the challenges that organizations face when implementing BERT in their systems:
- Data requirements: One of the biggest challenges of implementing BERT is the data requirements. BERT is a deep learning model, which means it requires a large amount of data to be trained. The original BERT model was trained on a dataset of over 3 billion words, which is an extremely large amount of data. If you don't have access to a large dataset, you may not be able to fully leverage the capabilities of BERT.
- Hardware requirements: BERT is a complex model, and training it requires a lot of computational power. You will need a powerful computer with a high-end GPU to train BERT effectively. This can be a challenge for organizations that do not have the necessary hardware or budget to invest in it.
- Training time: BERT is a slow model to train, and it can take days or even weeks to fully train the model depending on the dataset and hardware. This can be a challenge for organizations that need to get their systems up and running quickly.
- Fine-tuning: BERT is a general-purpose model, which means it can be used for a wide range of NLP tasks. However, it needs to be fine-tuned to perform well on a specific task. This requires a lot of time and effort, and you may need to experiment with different parameters and hyperparameters to find the best configuration for your specific use case.
- Integration with existing systems: Implementing BERT requires integration with your existing systems, which can be a challenge. You may need to modify your existing codebase or build new interfaces to integrate BERT into your systems. This can be a time-consuming and complex process, especially if you are working with legacy systems.
- Lack of expertise: Another challenge of implementing BERT is the lack of expertise in the field. BERT is a relatively new model, and there are not many experts who have experience working with it. This can make it difficult to find the right resources to help you implement BERT in your organization.
- Cost: Finally, implementing BERT can be expensive. You will need to invest in hardware, data, and expertise to get the most out of the model. This can be a challenge for organizations with limited budgets.
In conclusion, implementing BERT is not without its challenges. You will need to overcome issues such as data requirements, hardware requirements, training time, fine-tuning, integration with existing systems, lack of expertise, and cost. However, despite these challenges, the potential benefits of BERT are significant, and it is worth considering for organizations looking to improve their NLP capabilities.
How Is BERT Different From Previous Google Algorithms?
BERT, or Bidirectional Encoder Representations from Transformers, is a natural language processing (NLP) algorithm developed by Google.
It has gained significant attention in the field of NLP for its ability to understand and process natural language with high accuracy and efficiency.
However, BERT is different from previous Google algorithms in several ways.
One of the main differences between BERT and previous Google algorithms is the way it processes language. BERT uses a transformer architecture, which allows it to process language in a bidirectional manner. This means that it can take into account the context of words before and after the one being analyzed, rather than just the context of words preceding it, as was the case with previous algorithms. This allows BERT to better understand the meaning of words and sentences, resulting in more accurate language processing.
Another difference is the way BERT is trained. Previous Google algorithms were trained on a large dataset of human-labeled data, which was used to teach the algorithm to understand and classify different words and phrases. However, BERT was trained using unsupervised learning, which means it was not given any explicit labels or instructions on how to classify words. Instead, it was fed a large amount of data and left to learn patterns and relationships on its own.
This has resulted in BERT being able to understand language in a more natural and intuitive way, as it has learned from real-world examples rather than being explicitly told what to do.
In terms of performance, BERT has shown significantly improved accuracy compared to previous Google algorithms. It has been able to outperform previous algorithms on a range of NLP tasks, including sentiment analysis, question answering, and language translation. This is due to its ability to understand language in a more nuanced and contextual way, which allows it to better capture the meaning and intent of words and sentences.
BERT has also been designed to be more flexible and adaptable than previous algorithms. It can be fine-tuned for specific tasks or languages, allowing it to be used in a wide range of applications. This has made it a popular choice for developers and researchers looking to build NLP systems for specific use cases.
Overall, BERT is a significant advancement in the field of NLP, and it has the potential to revolutionize the way we interact with computers and machines. Its ability to understand and process natural language with high accuracy and efficiency makes it a powerful tool for a wide range of applications, from language translation to customer service chatbots. Its bidirectional processing and unsupervised learning capabilities set it apart from previous Google algorithms, and it has the potential to shape the future of artificial intelligence and machine learning.
How Has BERT Affected Search Engine Ranking Factors?
BERT, or Bidirectional Encoder Representations from Transformers, is a natural language processing (NLP) model developed by Google that has had a significant impact on search engine ranking factors. BERT was introduced in 2019 and has since been integrated into Google's search algorithms to improve the understanding of language and context in search queries.
One of the primary ways that BERT has affected search engine ranking factors is through its ability to better understand the intent behind search queries.
Prior to BERT, Google's algorithms would primarily focus on matching keywords in a search query to content on a webpage. However, BERT is able to understand the context and meaning behind a search query, allowing it to provide more relevant and accurate search results.
For example, if someone searches for "2019 best-selling books," BERT is able to understand that the searcher is looking for a list of the best-selling books in 2019, rather than a list of books that were sold the most in 2019. This has led to an improvement in the quality of search results, as users are more likely to find what they are looking for when the results are more closely aligned with their intent.
Another way that BERT has affected search engine ranking factors is through its ability to understand the relationships between words in a search query. Prior to BERT, Google's algorithms would often struggle to understand the meaning of phrases that contained multiple words, such as "best-selling books." BERT is able to understand the relationships between words in a phrase, allowing it to better understand the intent behind a search query and provide more relevant results.
BERT has also had an impact on the use of long-tail keywords in search engine optimization (SEO). Prior to BERT, long-tail keywords, or phrases that are more specific and less commonly searched, were often overlooked by search algorithms. This made it difficult for websites that relied on long-tail keywords to rank well in search results. However, BERT's ability to understand the meaning and context behind a search query has made it easier for websites that rely on long-tail keywords to rank well in search results.
In addition to its impact on search results, BERT has also affected the way that content is optimized for search engines. With BERT's ability to understand the meaning and context behind a search query, it is important for content creators to focus on providing high-quality, relevant information that is aligned with the intent of the searcher. This means that SEO strategies that rely on keyword stuffing or other tactics that are not focused on providing value to the user are less likely to be effective.
Overall, the introduction of BERT has had a significant impact on search engine ranking factors. Its ability to understand the intent behind a search query and the relationships between words has led to an improvement in the quality of search results, as well as a shift in the way that content is optimized for search engines. While BERT is just one factor among many that influence search rankings, it has undoubtedly had a significant impact on the way that search engines operate.
Will BERT Continue To Evolve And Improve Over Time?
BERT, or Bidirectional Encoder Representations from Transformers, is a language processing model developed by Google in 2018. \
It has quickly become one of the most widely used models in natural language processing (NLP), and has achieved impressive results in tasks such as question answering, translation, and sentiment analysis.
However, despite its impressive performance, it is likely that BERT will continue to evolve and improve over time.
In fact, Google has already released several updates to the model, including BERT-base, BERT-large, BERT-base-cased, and Sentence-BERT (now a part of Google's Multitask Unified Model, or MUM). These updates have increased the model's performance on various NLP tasks, and it is likely that further updates will be released in the future.
One reason for this continued evolution is the rapid pace of technological advancement in the field of NLP. As new techniques and approaches are developed, it is likely that they will be incorporated into BERT to improve its performance. For example, recent advances in deep learning techniques such as self-supervised learning and unsupervised learning have the potential to significantly improve BERT's performance on tasks such as language translation and language generation.
Another reason for the continued evolution of BERT is the increasing demand for NLP applications in various industries. From customer service chatbots to automated translation systems, there is a growing need for systems that can understand and process human language. As a result, companies and researchers are constantly seeking ways to improve the performance of NLP models like BERT in order to meet this demand.
One potential direction for the evolution of BERT is the integration of more advanced language processing capabilities. Currently, BERT is able to understand and process the meaning of words and sentences, but it is limited in its ability to understand more complex language concepts such as irony, sarcasm, and figurative language. As research in these areas advances, it is likely that BERT will be able to incorporate these capabilities, leading to more accurate and nuanced language processing.
Another potential direction for the evolution of BERT is the incorporation of more diverse language data. Currently, BERT is trained on a large corpus of text data, but this data is primarily in English and is largely from the internet. By incorporating more diverse language data, such as data from other languages or from other sources, BERT could potentially improve its performance on tasks such as translation and language generation.
Finally, it is likely that the evolution of BERT will involve a focus on improving its efficiency and scalability. Currently, BERT is a very resource-intensive model, requiring a large amount of computational power to run. As a result, it is not always practical to use BERT in real-time applications or in resource-constrained environments. By improving the efficiency of BERT, it could potentially be used in a wider range of applications and contexts.
In conclusion, it is likely that BERT will continue to evolve and improve over time. As new techniques and approaches are developed and the demand for NLP applications grows, it is likely that BERT will be updated to incorporate these advances and meet this demand. Potential directions for the evolution of BERT include the incorporation of more advanced language processing capabilities, more diverse language data, and improved efficiency and scalability.
How Market Brew Models Google's BERT
How Market Brew Models Google's BERT
Market Brew's search engine models utilize four distinct semantic algorithms: tf-idf, keywords, entities, and embeddings. Embeddings are modeled in Market Brew through the Search Generative Experience SGE Visualizer, which problem reduces into embeddings and BERT-like approaches to solving semantic classification.
This approach is able to analyze the language used in a query and determine the underlying intent behind it. This is similar to how BERT works, as it is also able to understand the relationships between words and their meanings in order to better interpret the intent of a query.
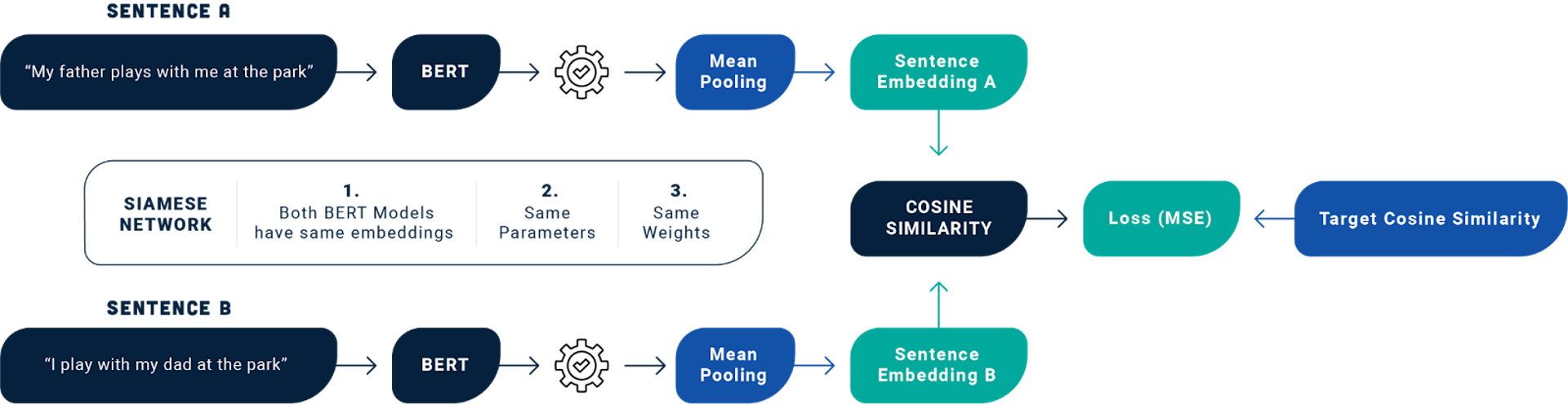
At its core, BERT processes text by breaking it down into word embeddings, which are dense vector representations of words that capture their semantic meaning. BERT embeddings encapsulate a rich understanding of language semantics.
Through the use of embeddings, BERT effectively transforms raw text into a format that can be easily understood and processed by machine learning algorithms, making it a cornerstone in modern natural language understanding.
Market Brew features the Search Generative Experience Author, which allows users to upload new content and see this transformation of content into vectors and embeddings.
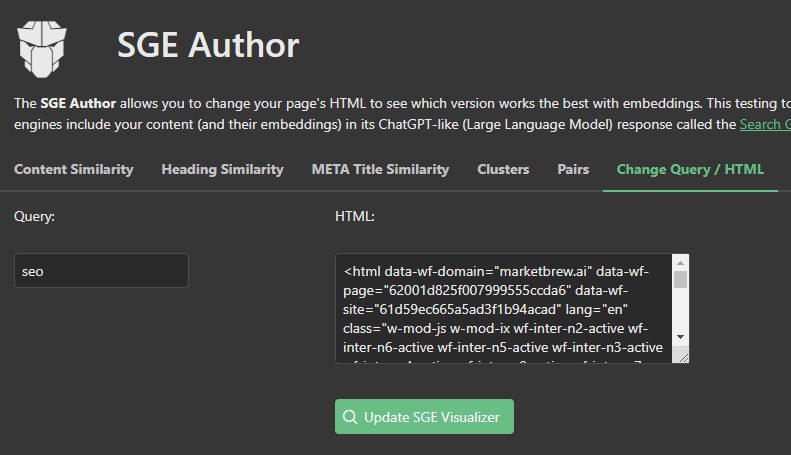
Market Brew models every major core algorithm in modern search engines.
Concurrently, Market Brew has crafted a model mirroring the likely strategies employed by BERT. This model enables digital marketers to grasp the algorithm's significance and discern the landing pages favored by Google.
Market Brew is a strong competitor in the SEO testing field, and its precise modeling at the first principles level allows it to provide an accurate model of how BERT affects SEO rankings.
Ready to Take Control of Your SEO?
See how Market Brew's predictive SEO models and expert team can unlock new opportunities for your site. Get tailored insights on how we can help your business rise above the competition.
Schedule a demonstration today via our Menu Button and Contact Form to discover how we engineer SEO success.
You May Also Like:
Information Extraction Best Practices for SEO
History
Google’s Medic Update
Guides & Videos
Dialogue Systems Improve User Experience And Boost SEO
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.