
Duplicate content is a common problem that many website owners face. It can have a negative impact on SEO, causing a website to be penalized by search engines.
In this article, we will explore the concept of duplicate content, how to identify it, and the consequences of having it on a website.
We will also discuss the best practices for removing duplicate content and avoiding it in the future.
Additionally, we will explore how Google handles duplicate content and how it affects SEO. We will also dispel some common misconceptions about duplicate content and SEO.
Duplicate content is a term used to describe content that is identical or very similar to content that already exists on a website or on the internet. This can be a problem for website owners because it can negatively impact the website's SEO. Search engines like Google can penalize websites with duplicate content, which can lead to a decrease in traffic and visibility.
In this article, we will explore the concept of duplicate content, how to identify it, and the consequences of having it on a website. We will also discuss the best practices for removing duplicate content and avoiding it in the future.
Additionally, we will explore how Google handles duplicate content and how it affects SEO. We will also dispel some common misconceptions about duplicate content and SEO.
By understanding the problem of duplicate content and how to address it, website owners can improve their SEO and increase their visibility on search engines.
What is Duplicate Content and How Does it Affect SEO?
Duplicate content is a term used to describe content that is identical or very similar to content that already exists on a website or on the internet. This can be a problem for website owners because it can negatively impact the website's SEO.
Search engines like Google can penalize websites with duplicate content, which can lead to a decrease in traffic and visibility.
Duplicate content can occur in a variety of ways. For example, a website owner may accidentally copy and paste content from another website without realizing it. In other cases, a website owner may create multiple pages with the same content, such as product pages with identical descriptions. Additionally, duplicate content can also occur when a website owner uses the same content on multiple domains or subdomains.
The problem with duplicate content is that it can cause confusion for search engines. When a search engine crawls a website, it tries to determine which pages are the most relevant for a particular search query. If there are multiple pages with the same content, the search engine may not know which page to rank higher in the search results. This can lead to a decrease in visibility for the website and a decrease in traffic.
To avoid penalties and negative impact on SEO, it's important to identify and remove duplicate content from your website. One way to do this is to use a tool like Copyscape, which allows you to check if your content is unique or if it appears elsewhere on the internet. Once you have identified any duplicate content, you can either remove it or use a rel="canonical" tag to tell search engines which page should be considered the original and indexed. Additionally, you can also use 301 redirects to redirect any duplicate pages to the original page, which will help search engines understand which page is the most relevant.
Another way to avoid duplicate content is to create original, high-quality content for your website. This will help to ensure that your website stands out in the search results and is not penalized for having duplicate content. Additionally, you can also use a content management system (CMS) that allows you to set up redirects and canonicals to prevent duplicate content from being created.
It's also important to note that some level of duplicate content is normal and can't be avoided, this is known as the "duplicate content filter" which is a common practice that search engines use to filter out near-duplicate content in order to prevent spamming. However, if the duplicate content is too much, it can negatively affect the SEO.
In summary, duplicate content can be a major problem for website owners because it can negatively impact SEO. By identifying and removing duplicate content, using rel="canonical" tags and 301 redirects, and creating original, high-quality content, website owners can improve their SEO and increase their visibility on search engines. Additionally, it's important to note that some level of duplicate content is normal and can't be avoided, but when it becomes too much, it should be addressed immediately.
How Can I Identify Duplicate Content on My Website?
Duplicate content is a common problem that many website owners face.
It can be caused by a variety of factors, such as copying and pasting content from other websites, having multiple versions of the same page, or even having a single page that is indexed under multiple URLs.
Regardless of the cause, duplicate content can have a negative impact on your website's search engine rankings and user experience.
There are several ways to identify duplicate content on your website, including:
- Use a plagiarism checker: There are a variety of online tools that can help you identify duplicate content on your website. These tools will scan your website and compare the content to other websites on the internet. If they find any matches, they will flag the content as duplicate. Some popular plagiarism checkers include Copyscape and Grammarly.
- Check Google Search Console: Google Search Console is a free tool that can help you identify duplicate content on your website. It will show you any pages that are being indexed under multiple URLs, as well as any pages that have been flagged as duplicate content by Google.
- Use a site audit tool: Site audit tools, such as SEMrush, Ahrefs, or Market Brew can help you identify duplicate content on your website by scanning your website and identifying any pages that have similar content. These tools will also provide you with a report that shows the exact pages that have duplicate content, as well as suggestions on how to fix the issue.
- Check for identical titles and descriptions: Another way to identify duplicate content on your website is to check for identical titles and descriptions on multiple pages. This can often be an indication that the content on those pages is also identical.
- Check for identical images: Similarly, checking for identical images on multiple pages can also be an indication of duplicate content. This can often happen when you use the same image on multiple pages without adding any text or context to it.
- Check for user-generated content (UGC): A major source of duplicate content can often by sections of your site that allow users to add comments or posts. These are sometimes out of your control, so you'll need to limit the exposure and find ways to reduce the chances of duplicate content being accidently added.
Once you have identified duplicate content on your website, it is important to take action to remove it. This can include removing the duplicate content, redirecting the duplicate pages to the original pages, or adding unique content to the duplicate pages.
One of the most effective ways to fix duplicate content is to use a 301 redirect. This tells the search engines that the duplicate page has been permanently moved to another URL. This will ensure that the original page is the one that is indexed and that the duplicate page is no longer being indexed.
Another solution is to use a rel=”canonical” tag. This tells the search engines that the page with the tag is the original page and any other pages with the same content should be ignored. This is a great solution if you have multiple pages with identical content but you don’t want to delete them.
In addition, you can also use the rel=”noindex” tag. This tells the search engines to not index a page. This is a great solution if you have a page that you don’t want to be indexed but you don’t want to delete it either.
Lastly, it is important to regularly check for duplicate content on your website. This will help you stay on top of any new duplicate content that may be created and take action to remove it before it can negatively impact your website's search engine rankings and user experience.
In conclusion, duplicate content can harm your website and its ranking on search engines. Identifying duplicate content is crucial in order to fix the issue as soon as possible. There are various tools and methods that can help you identify duplicate content on your website. Once you identify the duplicate content, you can then take action to remove it by redirecting, using a rel=”canonical” tag, or using the rel=”noindex” tag.
It is also important to regularly check for duplicate content on your website to ensure that it does not negatively impact your website's search engine rankings and user experience. By identifying and removing duplicate content, you can improve your website's search engine rankings and provide a better user experience for your visitors. Additionally, regularly checking for duplicate content will also help you to stay on top of any new duplicate content that may be created in the future.
Overall, identifying and removing duplicate content is an important step in maintaining a high-quality, well-optimized website.
What Are The Consequences Of Having Duplicate Content On My Website?
Duplicate content is a common problem that many website owners face. It is defined as content that is identical or very similar to content that already exists on a website or on the internet.
Having duplicate content on your website can have a number of negative consequences for your SEO and overall online presence.
The first and most obvious consequence of having duplicate content on your website is that it can lead to a decrease in traffic and visibility. Search engines like Google use complex algorithms to determine the relevance and quality of a website's content. When they encounter duplicate content, they may penalize the website by ranking it lower in search results. This can lead to a decrease in traffic and visibility, as fewer people will be able to find your website through search engines.
Another consequence of having duplicate content on your website is that it can harm your website's credibility and reputation. When people come across duplicate content, they may assume that the website is not trustworthy or credible. They may also assume that the website is not providing unique or valuable information. This can lead to a loss of trust and credibility in your brand, which can be difficult to regain.
Duplicate content can also lead to a loss of revenue. When search engines penalize a website for having duplicate content, the website may see a decrease in traffic and visibility. This can lead to a decrease in the number of people who visit the website and make a purchase. This can be especially problematic for e-commerce websites, which rely on traffic and visibility to generate revenue.
Additionally, having duplicate content on your website can also lead to poor user experience. When users encounter duplicate content, they may become confused or frustrated. They may also assume that the website is not providing unique or valuable information. This can lead to a higher bounce rate, as users leave the website quickly without engaging with the content.
To avoid these negative consequences, it's important to take steps to remove duplicate content from your website and to avoid creating it in the future. You can use tools like Google Search Console or Siteliner to identify any duplicate content on your website. Once you have identified the duplicate content, you can remove it or use canonicals to indicate to search engines which version of the content should be indexed. Additionally, it's important to create original and unique content for your website, rather than copying and pasting content from other sources.
In conclusion, having duplicate content on your website can have a number of negative consequences for your SEO and overall online presence. It can lead to a decrease in traffic and visibility, harm your website's credibility and reputation, lead to a loss of revenue, and poor user experience. To avoid these negative consequences, it's important to take steps to remove duplicate content from your website and to avoid creating it in the future. By creating original and unique content for your website, you can improve your SEO and increase your visibility on search engines.
How Can I Remove Duplicate Content From My Website?
Duplicate content can be a major issue for any website, as it can negatively impact your search engine rankings and make it more difficult for users to find the information they are looking for.
To remove duplicate content from your website, there are a few key strategies that you can use.
The first step in removing duplicate content from your website is to identify any areas where it may be present. This can be done by running a crawl of your website using a tool like Ahrefs, Market Brew, or SEMrush, which will provide you with a list of all the pages on your site and their duplicate content percentages. Once you have identified any pages with high levels of duplicate content, you can then take steps to remove or rewrite the content to make it unique.
One way to remove duplicate content from your website is to use a 301 redirect. This is a type of redirect that tells search engines that a page has permanently moved to a new location. By using a 301 redirect, you can redirect any duplicate content pages to the original page, which will help to eliminate the duplicate content and improve your search engine rankings.
Another strategy for removing duplicate content is to use the rel=canonical tag. This tag is used to tell search engines which version of a page should be considered the original and which version should be ignored. By using this tag, you can ensure that the search engines are only indexing the original version of your content and not any duplicate versions.
Rewriting the content is also a great way to remove duplicate content from your website. By rewriting the content, you can make it unique and more valuable to your users. This can also help to improve your search engine rankings, as search engines will be more likely to index your content if it is unique and relevant.
Another way to remove duplicate content from your website is to use the noindex tag. This tag tells search engines not to index a particular page or section of your site. By using the noindex tag, you can prevent search engines from indexing duplicate content and help to improve your search engine rankings.
In conclusion, duplicate content is a major issue for any website, as it can negatively impact your search engine rankings and make it more difficult for users to find the information they are looking for. To remove duplicate content from your website, there are a few key strategies that you can use, including using a 301 redirect, using the rel=canonical tag, rewriting the content, and using the noindex tag.
By using these strategies, you can eliminate duplicate content and improve your search engine rankings.
Is Having Some Duplicate Content On My Website Harmful To My SEO?
Duplicate content is a common issue that many website owners face. It occurs when a website has multiple pages with the same or similar content.
While it may seem harmless, having duplicate content on a website can have a negative impact on SEO. Let's answer whether having some duplicate content on a website is harmful to SEO.
First, it is important to understand how search engines handle duplicate content. When a search engine crawls a website, it looks for unique and relevant content. If the search engine finds multiple pages with the same content, it may not know which page to index or rank. This can lead to confusion and a decrease in visibility for the website. Additionally, search engines may penalize a website for having duplicate content, which can result in a lower ranking and less traffic.
However, it is important to note that not all duplicate content is created equal. Some duplicate content, such as product descriptions or manufacturer information, may not be harmful to SEO as long as it is properly labeled with canonicals or noindex tags. Canonicals are HTML tags that tell search engines which version of the content is the original, while noindex tags tell search engines not to index a certain page.
On the other hand, having duplicate content on the same website can be harmful to SEO. This includes having multiple pages with the same content, such as multiple blog posts with the same title and content, or having the same content on multiple domains. This can lead to search engines penalizing the website for having duplicate content, which can result in a lower ranking and less traffic.
Furthermore, having duplicate content can also affect the user experience. When a user searches for a certain topic and finds multiple pages with the same content, they may not know which page to trust or which page is the most relevant. This can lead to confusion and a decrease in trust in the website.
In conclusion, having some duplicate content on a website may not be harmful to SEO as long as it is properly labeled with canonicals or noindex tags.
However, having duplicate content on the same website or multiple domains can be harmful to SEO, as it can lead to a lower ranking and less traffic.
Additionally, having duplicate content can also affect the user experience, which can lead to confusion and a decrease in trust in the website. Website owners should take steps to identify and remove duplicate content from their website in order to improve their SEO and user experience.
How Can I Avoid Creating Duplicate Content On My Website?
Duplicate content is a common issue that many website owners face. It can harm your website's search engine rankings, lead to penalties from search engines, and decrease the user experience.
Here is how to avoid creating duplicate content on your website:
- Use Canonical URLs: A canonical URL is a way to tell search engines that a specific URL represents the master copy of a page. By using a canonical URL, you are telling search engines that the content on that page should be indexed and ranked, while any other versions of the page should be ignored. This is an effective way to prevent duplicate content issues.
- Use 301 Redirects: A 301 redirect is a way to permanently redirect one URL to another. This is an effective way to prevent duplicate content issues when you have multiple versions of a page or when you are moving content to a new URL. By using a 301 redirect, you are telling search engines that the old URL should be ignored, and the new URL should be indexed and ranked.
- Use Rel=”Noindex”: The rel=”noindex” tag is a way to tell search engines not to index a specific page. This is an effective way to prevent duplicate content issues when you have pages that are not important or do not add value to your website. By using the rel=”noindex” tag, you are telling search engines to ignore those pages, and they will not be indexed or ranked.
- Use Unique Content: One of the most effective ways to avoid creating duplicate content on your website is by using unique content. This means that the content on your website should be original and not copied from other sources. Search engines penalize websites that use duplicate content, so it is essential to use unique content on your website.
- Use a Content Management System (CMS): A Content Management System (CMS) is a software that allows you to easily manage your website's content. A CMS can help you avoid creating duplicate content by providing tools to help you manage your content and make sure that it is unique.
- Use a Duplicate Content Checker: A duplicate content checker is a tool that can help you identify duplicate content on your website. By using a duplicate content checker, you can quickly identify any duplicate content and take action to remove it.
In conclusion, creating duplicate content on your website can harm your website's search engine rankings and decrease the user experience.
To avoid creating duplicate content, you can use canonical URLs, 301 redirects, rel=”noindex”, rel=”canonical”, use unique content, use a Content Management System (CMS), and use a duplicate content checker.
By following these tips, you can ensure that your website is free from duplicate content and that it is optimized for search engines.
What Are The Best Practices For Dealing With Duplicate Content In SEO?
Duplicate content is a common issue that many website owners face when it comes to SEO. It refers to content that is identical or very similar to content that already exists on a website or on the internet.
This can be a problem for website owners because it can negatively impact the website's SEO. Search engines like Google can penalize websites with duplicate content, which can lead to a decrease in traffic and visibility.
Therefore, it is essential for website owners to understand the best practices for dealing with duplicate content in SEO.
The first step in dealing with duplicate content is to identify it. There are several tools available that can help website owners identify duplicate content on their websites. Some popular options include Google Search Console, Copyscape, and Siteliner.
These tools can scan a website and identify any pages with duplicate content. Once the duplicate content has been identified, website owners can take steps to remove it.
The next step is to remove the duplicate content from the website. This can be done by deleting the duplicate content or by using a 301 redirect to redirect the duplicate content to the original content. It is important to note that removing duplicate content from a website can take some time and effort. However, it is essential to do so in order to improve the website's SEO.
Another best practice for dealing with duplicate content is to use canonicals. Canonicals are a way of telling search engines which version of a page is the original and should be indexed. This can help to avoid duplicate content issues. When using canonicals, it is important to ensure that they are implemented correctly to avoid any confusion for search engines.
Another best practice is to avoid creating duplicate content in the first place. This can be done by creating original and unique content for the website. A good copywriting strategy can be achieved by conducting thorough research, using a variety of sources, and using different writing styles. Additionally, it is important to avoid scraping content from other websites and republishing it on your own website.
Lastly, it is important to understand that Google handles duplicate content differently from other search engines. Google is able to identify the original content and will not penalize the website for having duplicate content if it is the original copy. However, it is still important to remove internal duplicate content to avoid any confusion for search engines and to maximize your site's efficiency.
In conclusion, duplicate content can be a major issue for website owners when it comes to SEO. The best practices for dealing with duplicate content include identifying it, removing it, using canonicals, avoiding creating duplicate content in the first place, and understanding how Google handles duplicate content. By following these best practices, website owners can improve their SEO and increase their visibility on search engines.
How Can I Use Canonicals To Deal With Duplicate Content On My Website?
Duplicate content is a common issue that many website owners face. It can be caused by a variety of factors such as having multiple URLs for the same page, syndicating content across multiple sites, or even just having similar content on different pages of your own website.
This can be a problem for a few reasons.
Firstly, it can negatively impact your search engine rankings as search engines may not know which version of the content to index. Secondly, it can lead to a poor user experience as users may be directed to multiple versions of the same page.
One way to deal with duplicate content is by using canonicals. A canonical tag, also known as a "rel canonical" tag, is a HTML element that tells search engines which version of a page should be considered the original and authoritative version. This helps to prevent confusion and ensure that only one version of the page is indexed by the search engine.
To implement canonicals on your website, you will need to add a "rel=canonical" tag to the head section of the duplicate pages. The tag should contain the URL of the original, authoritative version of the page.
For example, if you have a page with the URL "example.com/page1" that is being duplicated on "example.com/page2", you would add the following tag to the head section of "example.com/page2":
<link rel="canonical" href="; />
It is important to note that canonicals are not a redirect, they do not redirect users or search engines to the original page. They simply tell search engines which version of the page should be considered the original. This means that users may still see the duplicate page, but search engines will know to index the original version.
Another way to deal with duplicate content is by using 301 redirects. A 301 redirect is a permanent redirect that sends users and search engines from one URL to another. This is a good option if you want to redirect users to the original version of the page and ensure that only one version of the page is indexed by search engines. However, it is important to note that 301 redirects can have a negative impact on the user experience as it will redirect users to a different URL than the one they originally clicked on.
It is also important to note that canonicals can be used in combination with 301 redirects.
For example, if you have a page with the URL "example.com/page1" that is being duplicated on "example.com/page2" and "example.com/page3", you could use a 301 redirect to redirect users and search engines from "example.com/page2" and "example.com/page3" to "example.com/page1". Then, you could use a canonical tag to tell search engines that "example.com/page1" is the original version of the page.
In conclusion, duplicate content can be a major issue for website owners. However, by using canonicals and 301 redirects, you can help to ensure that only one version of a page is indexed by search engines and that users are directed to the original version of the page. It is important to note that canonicals and 301 redirects can be used together to create the best possible solution for your website. Additionally, it is important to regularly review your website for any duplicate content and to address it as soon as possible.
How Does Google Handle Duplicate Content And How Does It Affect My SEO?
Duplicate content is a common problem for many website owners. It occurs when a website has multiple pages with the same or very similar content. This can be a problem for website owners because it can negatively impact the website's SEO.
Google and other search engines can penalize websites with duplicate content, which can lead to a decrease in traffic and visibility. In this article, we will explore how Google handles duplicate content and how it affects SEO.
When Google crawls a website, it looks for unique and valuable content. When it finds multiple pages with the same or very similar content, it may consider them to be duplicate content. This can be a problem because Google may not know which page to show in search results. In some cases, Google may choose not to show any of the pages in search results, which can result in a decrease in traffic and visibility.
Google uses a few different techniques to handle duplicate content. One technique is to use a canonical tag, which is a way to tell Google which page is the original and which pages are duplicates. This helps Google understand which page to show in search results.
Another technique is to use 301 redirects, which redirects users from the duplicate page to the original page. This also helps Google understand which page to show in search results.
Despite these techniques, Google may still penalize a website with duplicate content. This can happen when a website has a large amount of duplicate content, or when the duplicate content is not easily identifiable by Google. In these cases, Google may lower the website's search engine ranking, which can result in a decrease in traffic and visibility.
One of the best ways to avoid a penalty from Google is to ensure that your website has unique and valuable content. This means avoiding duplicate content and ensuring that all of your content is original. Additionally, it's important to use the canonical tag and 301 redirects to help Google understand which pages are duplicates and which pages are the original.
In conclusion, duplicate content can be a problem for website owners because it can negatively impact SEO. Google handles duplicate content by using techniques such as canonical tags and 301 redirects, but it may still penalize a website with duplicate content.
To avoid penalties, website owners should ensure that their website has unique and valuable content, and use the canonical tag and 301 redirects to help Google understand which pages are duplicates and which pages are the original.
By understanding how Google handles duplicate content and how it affects SEO, website owners can take steps to improve their SEO and increase their visibility on search engines.
What Are The Common Misconceptions About Duplicate Content And SEO?
Duplicate content is a topic that is often discussed in the world of SEO, but there are many misconceptions about what it is and how it affects a website's search engine rankings.
In this article, we will explore some of the most common misconceptions about duplicate content and SEO, and provide the truth behind them.
Misconception #1: Duplicate content will get your website penalized by Google
One of the most common misconceptions about duplicate content is that it will get your website penalized by Google. This is simply not true. Google's algorithm is designed to understand that duplicate content can occur naturally and is not always a sign of malicious intent. In fact, Google has stated that they do not penalize websites for having duplicate content. However, they do recommend that webmasters take steps to minimize the amount of duplicate content on their site, in order to provide the best possible user experience.
Misconception #2: All duplicate content is bad
Another misconception about duplicate content is that all duplicate content is bad and should be avoided at all costs. This is also not true. In fact, there are many instances where duplicate content is necessary and even beneficial. For example, if you have a product or service that is available in multiple languages, it is perfectly acceptable to have the same content translated and displayed on different pages of your website. Additionally, if you have a blog or news site, it is common for articles to be republished on other sites with a link back to the original source. In these cases, the duplicate content is not only acceptable, but it can also help to increase visibility and drive traffic to your website.
Misconception #3: Duplicate content only refers to text
Another misconception about duplicate content is that it only refers to text. This is not the case. Duplicate content can also refer to images, videos, and other types of media. For example, if you have an image on your website and another website uses that same image without permission, it is considered duplicate content. Additionally, if you have a video on your website and someone uploads that same video to their own website, it is also considered duplicate content. It is important to keep in mind that duplicate content can refer to any type of media and not just text.
Misconception #4: Duplicate content is only a problem on external websites
Another misconception about duplicate content is that it is only a problem on external websites. This is not true. In fact, duplicate content can also occur on your own website. For example, if you have a product or service that is listed on multiple pages of your website, it is considered duplicate content. Additionally, if you have a blog or news site, it is common for articles to be republished on other sections of your website. In these cases, the duplicate content is not only a problem, but it can also negatively impact your search engine rankings.
In conclusion, duplicate content is a topic that is often misunderstood in the world of SEO. It is important to understand that not all duplicate content is bad, and that it can occur naturally and even be beneficial. Additionally, duplicate content can refer to any type of media, not just text, and can occur on both external and internal websites. By understanding the truth behind these misconceptions, webmasters can take the necessary steps to minimize the amount of duplicate content on their site and improve their search engine rankings.
Modeling Tf-Idf in Market Brew
Avoiding Duplicate Content With Search Engine Modeling
Duplicate content can be a major issue for website owners, as it can negatively impact their SEO and visibility on search engines.
However, with the right tools and techniques, it is possible to avoid duplicate content and improve your website's performance.
Market Brew's SEO software, which uses search engine models to give users a clear picture of what the search engines see, can significantly reduce the amount of duplicate content issues a site has.
One of the key features of Market Brew's software is its ability to correlate content within a site to see the level of content overlap between pairs of content. This is important because it allows users to identify and address duplicate content before it becomes a problem.
According to Market Brew's research, content correlation below 50% is not penalized by search engines, while content correlation above 50% can lead to ranking decreases.
Market Brew's SEO software also alerts users to other potential duplicate content issues, such as duplicate meta titles, duplicate market focus (keyword-based), duplicate spotlight focus (entity-based), and internal link loss.
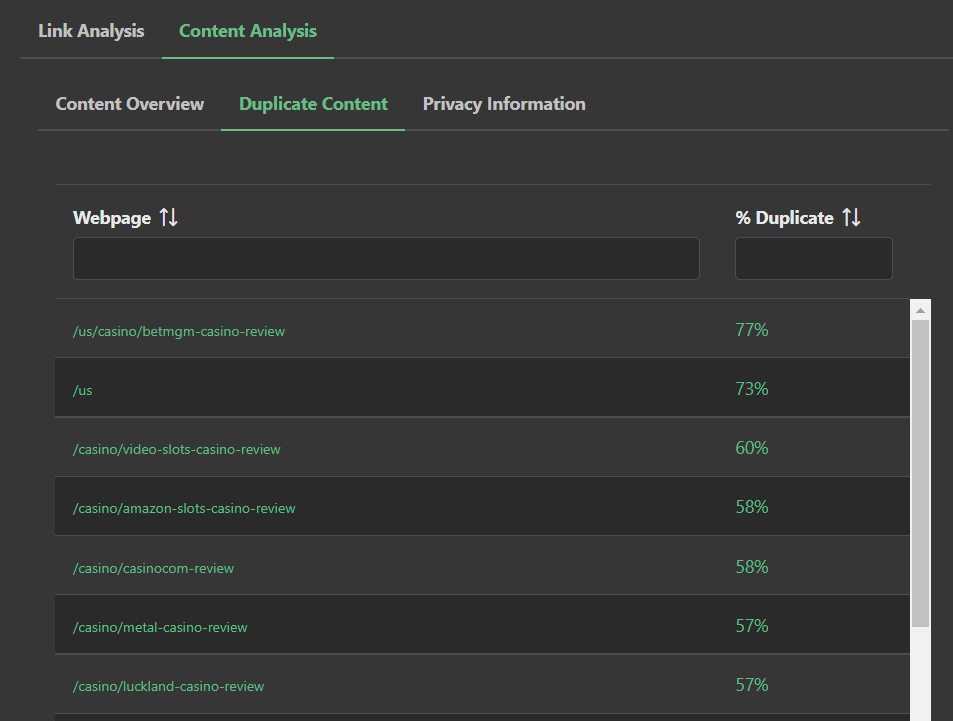
Internal link loss occurs when duplicate content effectively masks parts of the link graph and makes that link equity unusable.
By identifying these issues and addressing them early, website owners can ensure that their website is fully optimized for search engines.
One of the most effective ways to deal with duplicate content is to use canonical tags.
Market Brew's search engine models will correctly remove the modeled penalties whenever an appropriate canonical tag is added to the duplicate pair (as long as the pair is less than 5% different in content).
Additionally, Market Brew's SEO software also shows users how any 301 redirects redistribute link equity using the Link Flow Distribution screen.
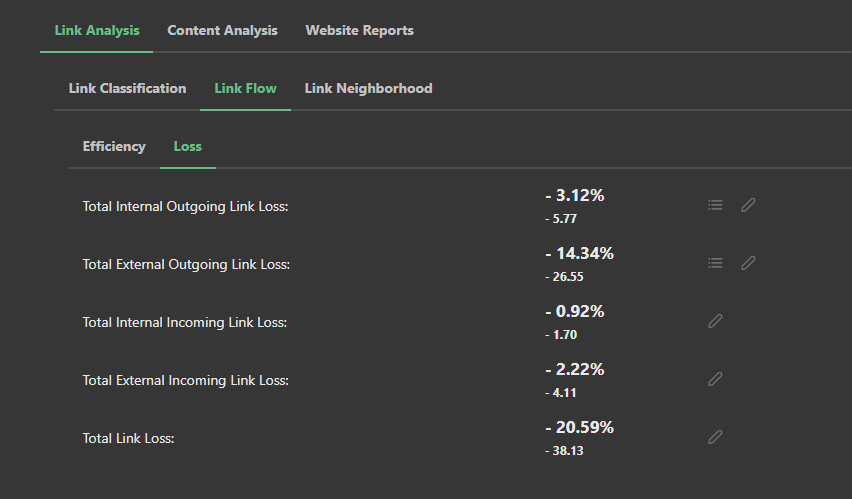
In conclusion, duplicate content can be a major issue for website owners, but with the right tools and techniques, it is possible to avoid it and improve your website's performance.
Market Brew's SEO software is one such tool that can help you identify and address duplicate content, and ensure that your website is fully optimized for search engines.
With Market Brew's search engine models, you can be sure that your website is running smoothly and that you're not losing any potential traffic or visibility.
You May Also Like:
Guides & Videos
Others
The Ultimate Guide for Visual Search Optimization (VSO)
Guides & Videos
Others
Google’s Helpful Content Update (HCU)
Guides & Videos
Others
Page Authority Importance in SEO
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.