
The Role of TF-IDF in Modern SEO Strategies
TF-IDF, or term frequency-inverse document frequency, is a statistical measure used to evaluate the importance of a word within a document in relation to a corpus of documents.
It is commonly used in information retrieval and natural language processing tasks, such as search engine optimization.
In this paper, we discuss the role of TF-IDF in modern search engine optimization strategies, including how it is used to improve search engine rankings and visibility. We also provide practical tips for optimizing your website for search engines using TF-IDF.
Search engine optimization (SEO) is the process of improving the ranking and visibility of a website on search engines such as Google. One important factor in SEO is the relevance and quality of the content on a website, as this affects how search engines perceive the website and how likely they are to show it in search results.
TF-IDF is a tool that can be used to optimize the content of a website for search engines by identifying the most important words and phrases within a document and ensuring that they are used prominently and appropriately.
In this paper, we explore the role of TF-IDF in modern search engine optimization strategies and provide guidance on how to use it effectively.
What Is The TF-IDF Algorithm And How Does It Work?
The tf-idf (term frequency-inverse document frequency) algorithm is a statistical measure used to evaluate the importance of a word or term in a document or collection of documents. It is commonly used in natural language processing and information retrieval tasks, such as document classification and information retrieval systems.
The algorithm works by calculating the term frequency (tf) of a word or term in a document, which is the number of times the word appears in the document divided by the total number of words in the document. The inverse document frequency (idf) is then calculated for each word or term, which is the logarithm of the total number of documents in the collection divided by the number of documents containing the word or term. The tf-idf score for a word or term in a document is calculated by multiplying the tf and idf values for the word.
The idea behind the tf-idf algorithm is that words or terms that are more common in a document are generally less informative or important, while words or terms that are less common in the document but more common in the collection of documents as a whole are considered more important or informative. This is because words or terms that are more common in the document are likely to be less specific to the content of the document, while words or terms that are less common in the document but more common in the collection as a whole are likely to be more specific to the content of the document.
For example, if the word "cat" appears frequently in a document about cats, it is likely to have a low tf-idf score, since it is common in the document but may not be very specific to the content of the document. On the other hand, if the word "feline" appears less frequently in the document but is more common in a collection of documents about cats, it is likely to have a higher tf-idf score, since it is less common in the document but more specific to the content of the document.
How is the TF-IDF Score of a Word or Term Calculated?
The tf-idf score of a word or term in a document is calculated by multiplying the term frequency (tf) and inverse document frequency (idf) values for the word.
The term frequency (tf) of a word or term in a document is calculated by dividing the number of occurrences of the word in the document by the total number of words in the document. For example, if the word "cat" appears 5 times in a document with 100 total words, the tf for the word "cat" in the document would be 0.05.
The inverse document frequency (idf) of a word or term is calculated by taking the logarithm of the total number of documents in the collection divided by the number of documents containing the word or term.
For example, if there are 1000 total documents in a collection and 50 of them contain the word "cat", the idf for the word "cat" in the collection would be log(1000/50) = 1.3.
The tf-idf score for a word or term in a document is then calculated by multiplying the tf and idf values for the word. For example, if the tf for the word "cat" in a document is 0.05 and the idf for the word "cat" in the collection is 1.3, the tf-idf score for the word "cat" in the document would be 0.065.
How Can the TF-IDF Algorithm Be Used to Improve Information Retrieval or Document Classification Tasks?
The tf-idf algorithm can be used to improve information retrieval or document classification tasks by weighting the importance of words or terms in a document or collection of documents.
By calculating the tf-idf scores for each word or term, the algorithm can identify the most important or relevant words or terms in a document or collection, which can be used to improve the accuracy and effectiveness of information retrieval or document classification systems.
For example, in an information retrieval system, the tf-idf algorithm can be used to rank search results based on the relevance of the documents to the search query. By calculating the tf-idf scores for each word or term in the search query and the documents in the collection, the system can identify the documents that are most relevant to the search query and rank them higher in the search results. This can help users find the most relevant and useful information more quickly and efficiently.
The tf-idf algorithm can also be used to improve document classification tasks, such as categorizing documents based on their content or topic cluster. By calculating the tf-idf scores for each word or term in the document, the algorithm can identify the words or terms that are most important or relevant to the content of the document. This information can then be used to accurately classify the document into a particular category or topic.
How Does the TF-IDF Algorithm Take Into Account the Context and Importance of a Word or Term in a Document or Collection of Documents?
The tf-idf algorithm takes into account the context and importance of a word or term in a document or collection of documents by calculating the term frequency (tf) and inverse document frequency (idf) values for each word or term.
The term frequency (tf) measures the importance of a word or term in a specific document, based on the number of times it appears in the document compared to the total number of words in the document. Words or terms that appear more frequently in the document are given a higher tf value, while words or terms that appear less frequently in the document are given a lower tf value.
The inverse document frequency (idf) measures the importance of a word or term in a collection of documents, based on the number of documents in the collection that contain the word or term. Words or terms that are more common in the collection are given a lower idf value, while words or terms that are less common in the collection are given a higher idf value.
By combining the tf and idf values for each word or term, the tf-idf algorithm takes into account both the context of the word or term in a specific document and its importance in the collection of documents as a whole. This allows the algorithm to identify the words or terms that are most important or relevant to the content of a document or collection of documents.
Can the TF-IDF Algorithm Be Used for Both Single-Document and Multi-Document Analysis?
Yes, the tf-idf algorithm can be used for both single-document and multi-document analysis.
In single-document analysis, the tf-idf algorithm can be used to identify the most important or relevant words or terms in a single document. This can be useful for tasks such as document summarization or keyword extraction, where the goal is to identify the most important or relevant words or terms in a document.
In multi-document analysis, the tf-idf algorithm can be used to identify the most important or relevant words or terms in a collection of documents. This can be useful for tasks such as information retrieval or document classification, where the goal is to identify the most important or relevant words or terms in a collection of documents and use them to classify or retrieve specific documents or information.
The tf-idf algorithm can be used in multi-document analysis by calculating the tf-idf scores for each word or term in the collection of documents. This allows the algorithm to identify the words or terms that are most important or relevant to the content of the documents in the collection, which can be used to classify or retrieve specific documents or information.
For example, in an information retrieval system, the tf-idf algorithm can be used to rank search results based on the relevance of the documents to the search query. By calculating the tf-idf scores for each word or term in the search query and the documents in the collection, the system can identify the documents that are most relevant to the search query and rank them higher in the search results.
In document classification tasks, the tf-idf algorithm can be used to identify the most important or relevant words or terms in a collection of documents and use them to classify the documents into specific categories or topics. By calculating the tf-idf scores for each word or term in the documents, the algorithm can identify the words or terms that are most important or relevant to the content of the documents and use them to accurately classify the documents into the appropriate categories or topics.
Another key difference is the sheer size of large language models. These models are trained on massive datasets and can have billions of parameters, which allows them to capture a wide range of linguistic patterns and nuances. This allows them to perform well on a variety of language tasks, including tasks that require understanding of context or broader knowledge about the world.
Despite their impressive abilities, large language models are not without their limitations. One major limitation is the amount of computational power and resources required to train and run these models. This can make them impractical for some applications and can also raise concerns about their environmental impact. Additionally, large language models are still limited by the quality and biases of the data they are trained on. This can lead to errors or unfair treatment of certain groups in certain applications.
Overall, large language models represent an exciting development in the field of natural language processing. While they have their limitations, they have the potential to greatly improve our ability to process and generate human-like natural language. As these models continue to evolve and improve, we can expect to see them playing a larger role in a wide range of applications.
How Does the TF-IDF Algorithm Compare to Other Term Weighting Schemes, Such as Term Frequency or Binary Term Frequency?
The tf-idf algorithm is a more sophisticated term weighting scheme compared to simpler schemes such as term frequency or binary term frequency.
Term frequency is a simple term weighting scheme that assigns a weight to a word or term based on the number of times it appears in a document, without taking into account the importance of the word or term in the context of the document or a collection of documents. This can lead to common words or terms being given high weights, even if they are not particularly important or relevant to the content of the document.
Binary term frequency is a slightly more advanced term weighting scheme that assigns a weight of 1 to a word or term if it appears in a document and a weight of 0 if it does not. This scheme does not take into account the frequency of the word or term in the document, so common words or terms are not given higher weights.
The tf-idf algorithm is a more sophisticated term weighting scheme that takes into account both the frequency of the word or term in a document (tf) and its importance in the context of a collection of documents (idf). This allows the algorithm to more accurately identify the words or terms that are most important or relevant to the content of a document or collection of documents.
How Can the Parameters of the TF-IDF Algorithm, Such as the Weighting Factor for Term Frequency and Inverse Document Frequency, Be Adjusted to Improve Performance on a Specific Task?
The parameters of the tf-idf algorithm, such as the weighting factor for term frequency and inverse document frequency, can be adjusted to improve performance on a specific task by modifying the way the tf and idf values are calculated.
For example, the weighting factor for term frequency can be adjusted by using a different function to calculate the tf value for each word or term. One common function used to calculate the tf value is the raw frequency of the word or term in the document, but other functions such as logarithmic scaling or double normalization can also be used.
The weighting factor for inverse document frequency can also be adjusted by using a different function to calculate the idf value for each word or term. One common function used to calculate the idf value is the logarithm of the total number of documents in the collection divided by the number of documents containing the word or term. However, other functions such as the logarithm of the total number of documents in the collection divided by the number of documents containing the word or term plus 1, or the logarithm of the total number of documents in the collection minus the number of documents containing the word or term, divided by the number of documents containing the word or term, can also be used.
Adjusting the weighting factors for term frequency and inverse document frequency can help to optimize the performance of the tf-idf algorithm for a specific task by changing the way the importance of each word or term is calculated. This can be useful for tasks such as information retrieval or document classification, where the goal is to identify the most important or relevant words or terms in a document or collection of documents.
Can the TF-IDF Algorithm Be Used in Combination with Other Natural Language Processing Techniques, Such as Stemming or Lemmatization?
Yes, the tf-idf algorithm can be used in combination with other natural language processing techniques, such as stemming or lemmatization, to improve the performance of information retrieval or document classification tasks.
Stemming is a natural language processing technique that involves reducing words to their base form, or stem, in order to identify the underlying meaning or concept. For example, the stem of the word "running" is "run", and the stem of the word "jumps" is "jump". By reducing words to their stems, stemming can help to improve the performance of information retrieval or document classification systems by allowing them to identify the underlying concepts or meanings of words, even if they are written in different forms.
Lemmatization is a similar natural language processing technique that involves reducing words to their base form, or lemma, in order to identify the underlying meaning or concept. Lemmatization is generally more sophisticated than stemming, as it takes into account the part of speech and grammatical context of a word in order to determine its lemma. For example, the lemma of the word "running" is "run", while the lemma of the word "jumps" is "jump", regardless of the part of speech or grammatical context in which they are used.
By using stemming or lemmatization in combination with the tf-idf algorithm, information retrieval or document classification systems can more accurately identify the underlying concepts or meanings of words, even if they are written in different forms, which can improve the performance of the systems.
How Can the TF-IDF Algorithm be Implemented in Practice, and What are Some Common Libraries or Packages That Provide Support for It?
The tf-idf algorithm can be implemented in a variety of programming languages, including Python, Java, and C++. There are also a number of libraries or packages that provide support for the tf-idf algorithm in these languages.
In Python, the scikit-learn library provides support for the tf-idf algorithm through its TfidfVectorizer class. This class allows users to easily calculate the tf-idf scores for words or terms in a document or collection of documents using a vector space model, and can be used in a variety of natural language processing tasks such as information retrieval or document classification.
In Java, the Lucene library provides support for the tf-idf algorithm through its TfidfSimilarity class. This class allows users to calculate the tf-idf scores for words or terms in a document or collection of documents, and can be used in a variety of information retrieval tasks.
In C++, the shogun library provides support for the tf-idf algorithm through its Tfidf class. This class allows users to calculate the tf-idf scores for words or terms in a document or collection of documents, and can be used in a variety of natural language processing tasks such as information retrieval or document classification.
There are also a number of other libraries or packages that provide support for the tf-idf algorithm in various programming languages, including the NLTK library in Python and the OpenNLP library in Java.
Are There Any Limitations or Drawbacks to Using the TF-IDF Algorithm, and in What Situations Might it Be Less Effective?
Like any statistical measure, the tf-idf algorithm has certain limitations and drawbacks that should be considered when deciding whether to use it for a specific task.
One potential limitation of the tf-idf algorithm is that it does not take into account the context or meaning of words or terms beyond their frequency or importance in a document or collection of documents. This can lead to words or terms being given high tf-idf scores even if they are not particularly relevant or important to the content of the document or collection.
Another potential limitation of the tf-idf algorithm is that it is sensitive to the size of the document or collection of documents being analyzed. In general, the tf-idf scores of words or terms are higher in smaller documents or collections, and lower in larger documents or collections. This can make it difficult to compare the tf-idf scores of words or terms across different documents or collections of different sizes.
Finally, the tf-idf algorithm can be less effective in situations where the documents or collection of documents being analyzed are not representative of the language or content of the task at hand. For example, if the documents in a collection are all written in a different language or about a different topic than the task being performed, the tf-idf algorithm may not be able to accurately identify the most important or relevant words or terms.
Overall, the tf-idf algorithm can be a useful tool for natural language processing tasks such as information retrieval or document classification, but it is important to carefully consider its limitations and potential drawbacks when deciding whether to use it for a specific task.
Understanding the Role of TF-IDF in Search Engine Ranking
TF-IDF, or term frequency-inverse document frequency, is a mathematical concept that is commonly used in the field of information retrieval and natural language processing. It is a measure of how important a specific word or term is within a document or collection of documents.
In the context of search engines, TF-IDF is used to determine the relevance of a web page to a particular search query. When a user enters a search query into a search engine, the search engine will use algorithms to rank the relevant web pages based on their relevance to the query. One of the factors that can influence the ranking of a web page is the presence and frequency of specific words or phrases that are related to the search query.
TF-IDF helps to determine the importance of a particular word or phrase by taking into account not only its frequency within a document, but also the frequency of the word or phrase in the entire collection of documents. This helps to ensure that common words, such as "the" and "and," are not given too much weight in the ranking process.
To understand how TF-IDF works, it's helpful to consider an example. Imagine that you have a collection of documents that are related to the topic of search engine optimization. One of the documents in the collection is a blog post about the importance of using keywords in website content. Within this blog post, the word "keywords" might be used multiple times.
However, if the word "keywords" is also used frequently in the other documents in the collection, it might not be given as much weight in the ranking process. On the other hand, if the word "TF-IDF" is not used very often in the other documents in the collection, but is used frequently in the blog post about keywords, it would be given more weight in the ranking process.
In summary, TF-IDF is a powerful tool that is used by search engines to determine the relevance of a web page to a particular search query. It helps to ensure that common words are not given too much weight in the ranking process, and it helps to identify the most important words and phrases within a document or collection of documents. By optimizing their content for TF-IDF, website owners can improve the visibility of their site in search engine results pages and drive more traffic to their site.
The Decline of TF-IDF in Search Engines
In recent years, the use of the tf-idf (term frequency-inverse document frequency) algorithm for search engine optimization (SEO) has declined, as newer and more advanced techniques have been developed for improving the relevance and accuracy of search results.
While the tf-idf algorithm was once a popular method for evaluating the importance of words or terms in a document or collection of documents, it has been largely replaced by other techniques that are more effective at identifying the most important or relevant words or terms for a given document or collection.
One reason for the decline in the use of the tf-idf algorithm for SEO is the emergence of more advanced natural language processing techniques. In the past, the tf-idf algorithm was often used in combination with techniques such as stemming or lemmatization in order to improve the accuracy of document classification. However, newer techniques such as word embedding and machine learning algorithms have proven to be more effective at identifying the underlying meanings or concepts of words and phrases, even in contexts where the words are written in different forms or used in different ways. As a result, these newer techniques have largely replaced the use of the tf-idf algorithm for SEO.
Another reason for the decline in the use of the tf-idf algorithm for SEO is the increasing importance of keyword, entity, and embedding-based approaches to classifying content. In fact, an entire semantic algorithm arc has been now established over the course of 20 years of search engineering.
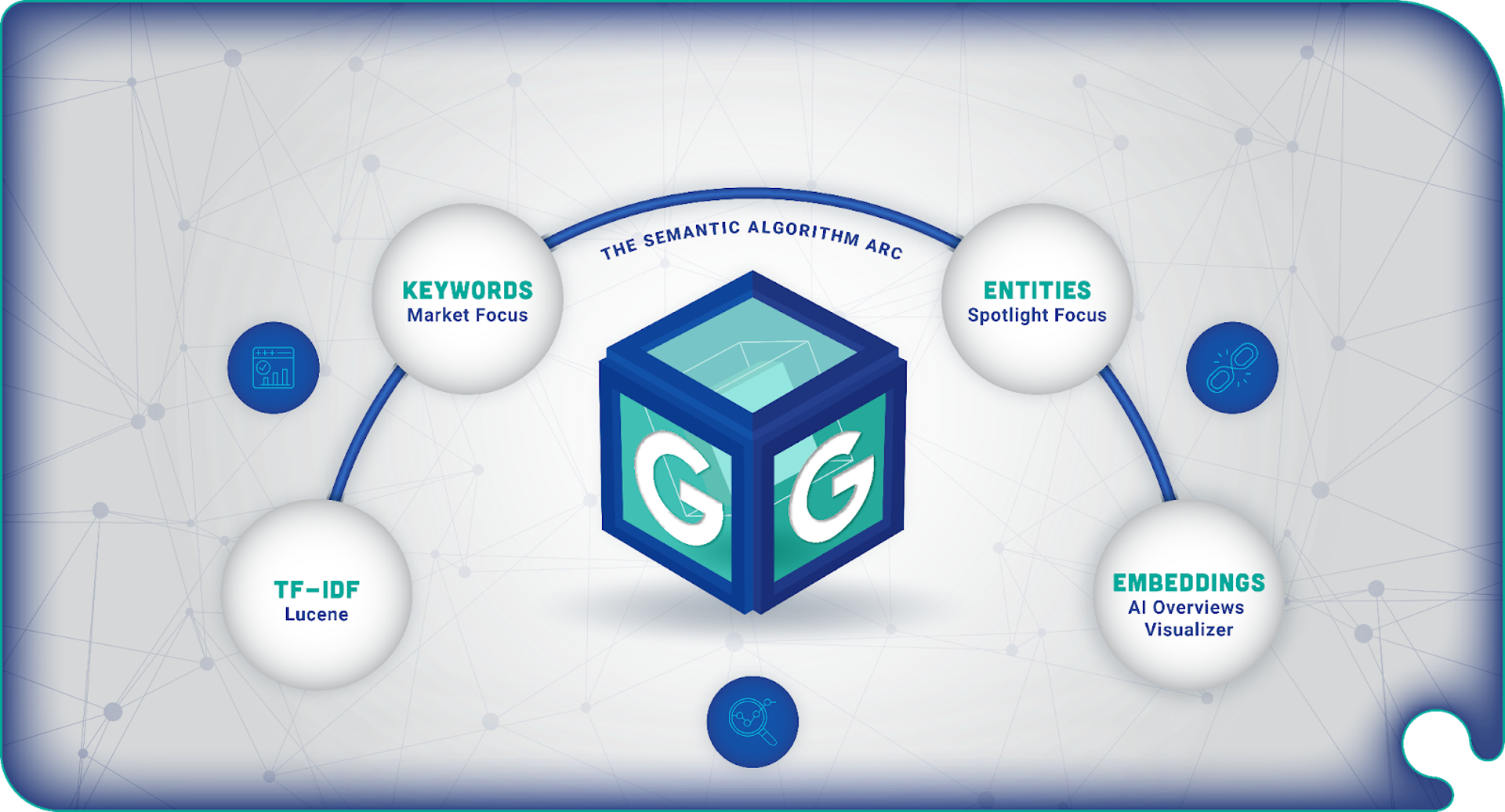
Additionally, machine learning algorithms are able to analyze large datasets of web pages and user behavior in order to identify patterns and trends that are not easily captured by traditional statistical measures such as the tf-idf algorithm. As a result, machine learning algorithms have become an important tool for improving the accuracy and relevance of search results, and have largely replaced the use of the tf-idf algorithm for SEO.
Overall, while the tf-idf algorithm was once a popular method for improving the relevance and accuracy of search results, it has largely been replaced by newer and more advanced techniques such as word embedding, machine learning algorithms, and the incorporation of user behavior and engagement into ranking algorithms. As a result, the use of the tf-idf algorithm for SEO has declined in recent years, and it is now used less frequently than it was in the past.
Modeling Tf-Idf in Market Brew
Modeling TF-IDF in Market Brew
For it's query layer, Market Brew uses Lucene, a powerful open-source library. One of the key features of Lucene is its query parser, which allows users to search for documents using a simple syntax that supports various types of queries, including boolean, phrase, and wildcard searches.
One of the algorithms used by the Lucene query parser is tf-idf, which stands for "term frequency-inverse document frequency."
Tf-idf is a measure of the importance of a term in a document, with higher values indicating that the term is more important to the content of the document.
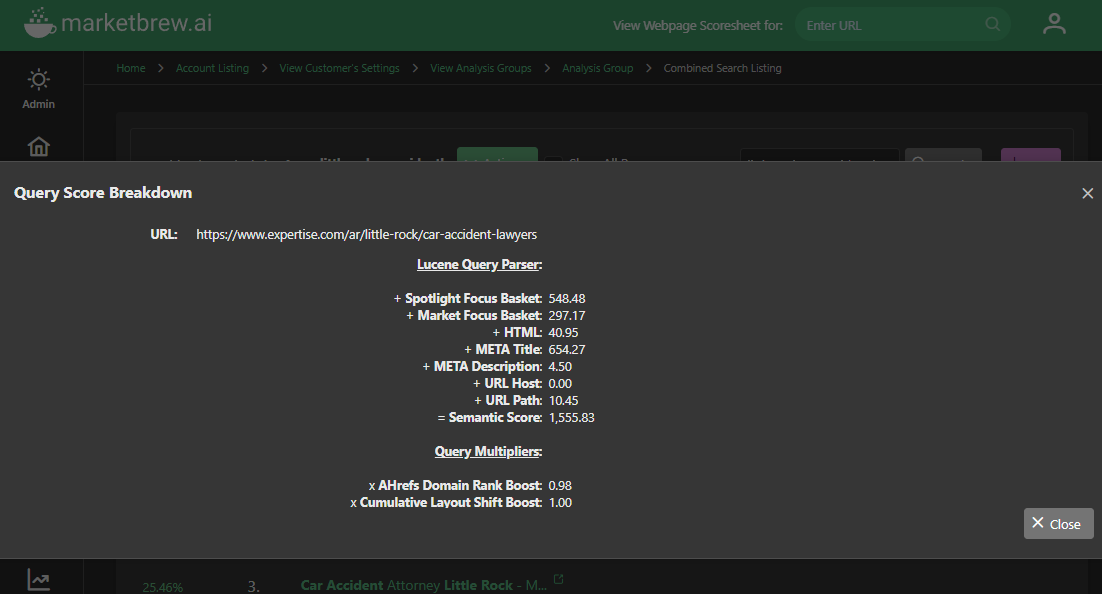
In the context of the Lucene query parser, tf-idf is used, among other algorithms, to rank the importance of terms in many fields, such as the HTML, META Title, and more.
It's importance is calibrated by Market Brew's Particle Swarm Optimization process, which determines how much this tf-idf algorithm is used, give the target search engine.
When a user enters a search query, the Lucene query parser calculates the tf-idf value for each term in the query and uses these values to score the documents in the index. The documents with the highest score are considered the most relevant and are returned to the user as search results.
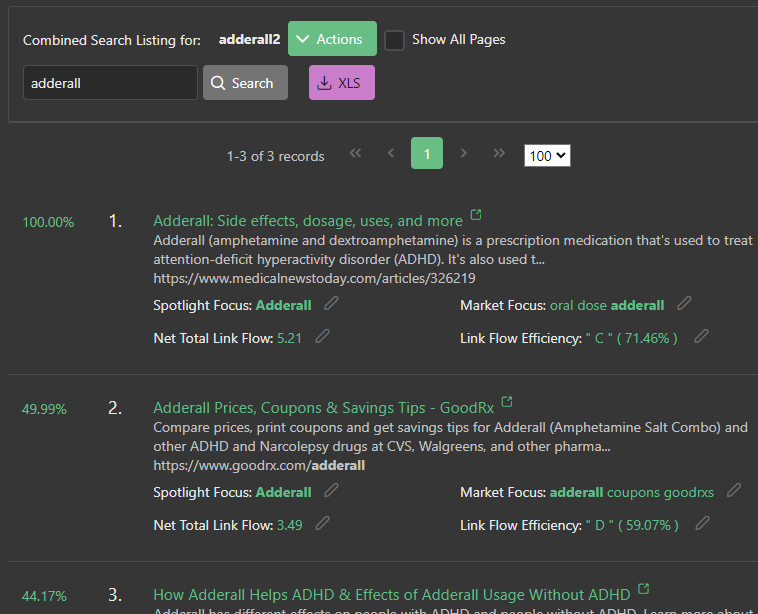
One of the key advantages of using tf-idf in the Lucene query parser is that it allows for more precise and relevant search results. By considering both the frequency and rarity of terms in both the search query and the indexed documents, tf-idf helps to ensure that the most relevant documents are returned to the user.
This can be particularly useful in cases where the search query contains rare or specialized terms, as these terms may not be present in many documents but are still important for finding relevant results.
In summary, the Lucene query parser uses the tf-idf algorithm to rank the importance of terms in a search query and to determine the relevance of documents in the index. This allows for more precise and relevant search results, and is an essential component of the full-text search capabilities of Lucene.
You May Also Like:
Guides & Videos
Benefits of Using Semantic Triples in SEO
History
Google RankBrain History
Guides & Videos
CSS and Stylesheets Improve SEO Performance
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.