
Word embeddings have become a popular tool in the field of search engine optimization (SEO).
In this article, we will explore the various ways in which word embeddings can be utilized to improve SEO efforts, including keyword analysis, content generation, and identification of synonyms and related terms.
We will also discuss the relationship between word embeddings and Latent Semantic Indexing (LSI), as well as the potential for using word embeddings to analyze user intent and translate content for localization purposes.
In the constantly evolving world of search engine optimization, it is essential for marketers and SEO professionals to stay up to date on the latest techniques and technologies. One such tool that has gained significant attention in recent years is word embeddings.
Word embeddings are a type of mathematical representation of words or phrases that capture the context and meaning of the words in a given text.
By analyzing these embeddings, it is possible to gain insights into the relationships between words and the overall meaning of a piece of content. In this article, we will delve into the various ways in which word embeddings can be utilized to improve SEO efforts and drive traffic to a website.
How Do Word Embeddings Help Improve SEO?
Word embeddings are a type of natural language processing (NLP) technique that involves representing words in a continuous, numerical vector space. This allows computers to understand and analyze the meanings of words and their relationships to one another in a more intuitive and accurate way.
In the context of search engine optimization (SEO), word embeddings can be used to improve the relevance and quality of search results. For example, word embeddings can help search engines understand the context in which a particular word is being used, allowing them to provide more relevant results for a given search query.
One way that word embeddings can help improve SEO is by providing a more accurate representation of the meaning of a word. Traditional techniques for representing words, such as bag-of-words or one-hot encoding, do not take into account the context in which a word is used or the relationships between words. This can lead to less accurate results, as a word may have different meanings depending on the context in which it is used.
Word embeddings, on the other hand, capture the relationships between words and their meanings in a more intuitive and accurate way. For example, a word embedding model might represent the word "dog" as being similar to the words "puppy" and "pet," while representing the word "cat" as being similar to the words "kitten" and "feline." This allows search engines to better understand the meanings of words and provide more relevant results for a given search query.
Another way that word embeddings can help improve SEO is by allowing search engines to better understand the context in which a word is being used. This can be particularly useful for long-tail keywords, which are specific, niche phrases that are less commonly searched for. Because word embeddings capture the relationships between words, they can help search engines understand the meaning of a long-tail keyword even if it is not an exact match for a word in the search query.
For example, if someone searches for "best dog food for small breeds," a search engine that uses word embeddings may be able to understand that the word "small" is modifying the word "breeds," and therefore provide results that are relevant to small dog breeds. This can help improve the relevance of search results and increase the likelihood that a user will find what they are looking for.
In addition to improving the relevance of search results, word embeddings can also help improve the quality of search results by allowing search engines to better understand the intent behind a search query. For example, if someone searches for "how to train a dog," a search engine that uses word embeddings may be able to understand that the user is looking for information on how to train a dog, rather than a product or service related to dog training. This can help ensure that search results are more relevant to the user's needs and improve the overall quality of the search experience.
Overall, word embeddings are a powerful tool for improving the relevance and quality of search results in SEO. By allowing computers to understand the meanings of words and their relationships to one another in a more intuitive and accurate way, word embeddings can help search engines provide more relevant and useful results for a given search query, improving the overall user experience and helping businesses to reach their target audience more effectively.
How Do Word Embeddings Help with Keyword Analysis and Targeting?
Word embeddings are a type of mathematical representation of words used in natural language processing (NLP) tasks. They are used to map words to a continuous vector space in a way that reflects the relationships between words in a given language.
Word embeddings can be useful for keyword analysis and targeting because they allow us to understand the meanings and relationships between words, as well as identify patterns and trends in text data.
In keyword analysis, word embeddings can help identify the most important or relevant words in a given text. This is useful for SEO purposes, as it allows companies to identify the keywords that are most likely to be used by users when searching for a particular product or service. By understanding the relationships between words, word embeddings can also help identify synonyms and related terms that may be useful for keyword targeting.
For example, if a company is selling outdoor gear, word embeddings can help identify keywords such as "hiking," "camping," and "backpacking" as being related to the company's products. This can be useful for identifying potential search terms that users may use when looking for the company's products.
In addition to identifying relevant keywords, word embeddings can also help with keyword targeting by allowing us to understand the context in which a given keyword is used. For example, if a company is selling outdoor gear, they may want to target the keyword "hiking" in the context of outdoor activities, rather than in the context of a job or school subject. Word embeddings can help identify the context in which a keyword is used, allowing companies to target their keywords more effectively.
Word embeddings can also be useful for identifying trends and patterns in text data. For example, if a company is analyzing customer reviews of their products, word embeddings can help identify common themes or trends in the language used by customers. This can be useful for identifying areas where the company can improve their products or services, as well as for identifying potential new product ideas.
Overall, word embeddings are a powerful tool for keyword analysis and targeting in natural language processing tasks. They allow us to understand the meanings and relationships between words, as well as identify patterns and trends in text data. This can be useful for a variety of purposes, including SEO, customer analysis, and product development.
Can Word Embeddings Be Used to Generate New Content Ideas or Phrases?
Word embeddings are a type of representation for words and phrases in natural language processing tasks. They are essentially numerical vectors that capture the meaning of words and the relationships between them in a multidimensional space.
Word embeddings are useful for various tasks such as language translation, sentiment analysis, and text classification.
One potential application of word embeddings is in generating new content ideas or phrases. Word embeddings can be used to identify patterns and relationships between words, which can provide insights into the underlying meaning and context of a text. This information can be used to generate new ideas or phrases that are related to the original text.
For example, let's say we have a text about the topic of sustainability. We can use word embeddings to identify the most relevant words and phrases associated with this topic, such as "green energy," "carbon footprint," and "environmental protection." We can then use these words and phrases to generate new content ideas or phrases that are related to sustainability.
One way to generate new content ideas or phrases using word embeddings is by performing word vector arithmetic. This involves adding or subtracting the word vectors of two or more words to generate a new word vector. For example, we can take the word vector of "sustainability" and add the word vector of "innovation," resulting in a new word vector that represents the concept of "sustainable innovation."
Another way to generate new content ideas or phrases using word embeddings is by using word embeddings to identify synonyms or similar words. We can use word embeddings to identify words that are similar to a given word or phrase, which can provide us with alternative ways to express a particular concept. For example, we can use word embeddings to identify synonyms for the word "sustainability," such as "green," "environmentally friendly," and "ecological."
Word embeddings can also be used to generate new content ideas or phrases by identifying relationships between words. For example, we can use word embeddings to identify words that are related to a particular topic, such as sustainability. This can help us identify new content ideas or phrases that are related to the topic, such as "sustainable agriculture" or "sustainable transportation."
In summary, word embeddings can be used to generate new content ideas or phrases by identifying patterns and relationships between words, performing word vector arithmetic, identifying synonyms and similar words, and identifying relationships between words. These techniques can provide valuable insights into the meaning and context of a text, which can be used to generate new content ideas or phrases that are relevant and informative.
How Do Word Embeddings Relate to Latent Semantic Indexing (LSI)?
Word embeddings are a type of representation used in natural language processing (NLP) tasks that involve processing and understanding large amounts of text. These representations aim to capture the meaning and context of words by representing them as numerical vectors in a high-dimensional space.
This allows words with similar meanings to be grouped together and enables NLP algorithms to better understand the relationships between words and their contexts.
Latent Semantic Indexing (LSI) is a technique used in information retrieval and natural language processing to identify the underlying themes or concepts within a large collection of documents. It is based on the idea that words with similar meanings will tend to appear in the same contexts, so by analyzing the patterns of co-occurrence of words within a document, we can identify the underlying themes or concepts.
One way to think about the relationship between word embeddings and LSI is that word embeddings can be seen as a more advanced and sophisticated version of LSI. Both techniques aim to capture the meanings and relationships between words, but word embeddings do this in a much more sophisticated and nuanced way.
One key difference between the two techniques is the way in which they represent words. LSI uses a technique called singular value decomposition (SVD) to reduce the dimensions of a document-term matrix, which is a matrix that represents the frequency of each word in a document. The SVD decomposition allows the matrix to be decomposed into a set of low-dimensional vectors, which represent the underlying themes or concepts within the documents.
Word embeddings, on the other hand, use a neural network-based approach to represent words as numerical vectors. These vectors are trained on large amounts of text data and are able to capture the relationships between words and their contexts in a much more sophisticated way than LSI. For example, word embeddings are able to capture the meanings of words in a much more nuanced way, taking into account the context in which the word appears and the relationships between words.
Another key difference between word embeddings and LSI is the way in which they are used in NLP tasks. LSI is primarily used in information retrieval tasks, such as searching for documents that are relevant to a given query. Word embeddings, on the other hand, are used in a wide range of NLP tasks, including language translation, text classification, and sentiment analysis.
Overall, word embeddings and LSI are two techniques that are used to represent and understand the meanings and relationships between words in large collections of text. While LSI is a useful technique for identifying the underlying themes or concepts within a collection of documents, word embeddings offer a much more sophisticated and nuanced way of representing words and their relationships.
Can Word Embeddings Be Used to Identify Synonyms or Related Terms for a Given Keyword?
Word embeddings are a type of representation for text data that maps words to numerical vectors. These vectors capture the meaning and context of words, allowing them to be used in various natural language processing (NLP) tasks. One of these tasks is identifying synonyms or related terms for a given keyword.
One way to use word embeddings for this task is by calculating the cosine similarity between the word embedding of the given keyword and the word embeddings of other words in the vocabulary. The cosine similarity measures the similarity between two vectors by comparing the angle between them. A high cosine similarity indicates that the vectors are similar, while a low cosine similarity indicates that they are dissimilar.
For example, if we have the word embeddings for the words "happy" and "joyful", we can calculate their cosine similarity to see how similar they are. If the cosine similarity is high, we can say that "happy" and "joyful" are synonyms. Similarly, we can calculate the cosine similarity between the word embedding of a given keyword and the word embeddings of other words in the vocabulary to identify synonyms or related terms.
Another way to use word embeddings for this task is by using a pre-trained word embedding model. These models have already been trained on a large dataset, and they have learned the meanings and contexts of words in the language. By using a pre-trained model, we can easily get the word embeddings for a given keyword and use them to identify synonyms or related terms.
For example, let's say we want to identify synonyms or related terms for the keyword "dog". We can use a pre-trained word embedding model to get the word embeddings for "dog" and other words in the vocabulary. We can then use the cosine similarity to compare the word embeddings of "dog" with the word embeddings of other words in the vocabulary. If the cosine similarity is high, we can say that the other word is a synonym or a related term for "dog".
In addition to the cosine similarity, there are also other techniques that can be used to identify synonyms or related terms using word embeddings. One of these techniques is called nearest neighbors. This technique finds the words in the vocabulary that are most similar to a given keyword by finding the word embeddings that are closest to the word embedding of the keyword.
For example, let's say we want to find the synonyms or related terms for the keyword "cat". We can use the nearest neighbors technique to find the words in the vocabulary that are most similar to "cat" by finding the word embeddings that are closest to the word embedding of "cat". These words are likely to be synonyms or related terms for "cat".
Another technique that can be used to identify synonyms or related terms using word embeddings is called word analogies. This technique allows us to find words that have a similar meaning to a given keyword but are used in different contexts. For example, if we have the word embeddings for the words "king" and "queen", we can use the word analogies technique to find words that have a similar meaning to "king" but are used in different contexts. These words might include "ruler" or "monarch".
In conclusion, word embeddings can be used to identify synonyms or related terms for a given keyword. There are several techniques that can be used for this task, including the cosine similarity, nearest neighbors, and word analogies. These techniques allow us to find words that are similar to a given keyword based on their meanings and contexts, which is useful for tasks such as text classification, information retrieval, and language translation.
However, it is important to note that word embeddings are not perfect and may not always accurately identify synonyms or related terms. The accuracy of word embeddings depends on the quality of the data used to train them and the technique used to calculate the word embeddings. It is also important to consider the context in which the words are used, as the meaning of a word may change depending on the context.
Overall, word embeddings can be a useful tool for identifying synonyms or related terms for a given keyword, but it is important to use them in conjunction with other techniques and to consider the limitations of word embeddings.
Can Word Embeddings Be Used to Identify the Sentiment or Emotion Associated with a Given Keyword or Phrase?
Word embeddings are a type of representation of words in a mathematical vector space, where each word is represented by a numerical vector.
These vectors are trained using machine learning algorithms on large amounts of text data and are designed to capture the context and meaning of words in a way that is similar to how humans understand language.
One potential application of word embeddings is to identify the sentiment or emotion associated with a given keyword or phrase.
There are several ways in which word embeddings can be used to identify the sentiment or emotion associated with a given keyword or phrase. One approach is to use word embeddings to create a sentiment or emotion lexicon, which is a list of words or phrases that are associated with particular sentiments or emotions. For example, a sentiment lexicon might include words like "happy," "sad," "angry," and "fearful," which are commonly associated with particular emotions.
To create a sentiment or emotion lexicon using word embeddings, one could start by selecting a set of words or phrases that are known to be associated with particular sentiments or emotions. These could be words or phrases that have been annotated by humans for sentiment or emotion, or they could be words or phrases that are commonly used in social media or other online platforms to express particular sentiments or emotions.
Once a set of words or phrases has been selected, the next step would be to use word embeddings to create vectors for each of these words or phrases. These vectors could be created using a pre-trained word embedding model, or they could be created from scratch using machine learning algorithms and a large dataset of text data.
Once the vectors for the words or phrases in the lexicon have been created, they can be used to identify the sentiment or emotion associated with other words or phrases. For example, if a word or phrase is found to be similar to a vector in the lexicon that is associated with a particular sentiment or emotion, it can be inferred that the word or phrase is also associated with that sentiment or emotion.
Another approach to using word embeddings to identify the sentiment or emotion associated with a given keyword or phrase is to use them as features in a machine learning model. In this case, the word embeddings would be used as input to a machine learning model, along with other features such as part-of-speech tags or grammatical structure, to predict the sentiment or emotion associated with a given keyword or phrase.
One example of this approach is the use of word embeddings in sentiment analysis, which is the process of automatically identifying the sentiment or emotion expressed in a piece of text. Sentiment analysis is often used in marketing and customer service to analyze customer feedback or to monitor social media for sentiment about a particular product or brand.
In sentiment analysis, word embeddings can be used as features in a machine learning model to predict the sentiment of a piece of text. For example, a machine learning model might use word embeddings as input, along with other features such as part-of-speech tags or grammatical structure, to predict whether a piece of text is positive, negative, or neutral in sentiment.
Overall, word embeddings can be a powerful tool for identifying the sentiment or emotion associated with a given keyword or phrase. Whether used to create a sentiment or emotion lexicon or as features in a machine learning model, word embeddings can provide a rich, context-aware representation of language that is well-suited to identifying the sentiment or emotion associated with particular words or phrases.
How Can Word Embeddings Be Used to Improve the Accuracy of Autocomplete or Predictive Text Features?
Word embeddings are a type of numerical representation of words used in natural language processing (NLP) tasks. They are created by training a machine learning model on a large dataset of text, and the resulting embeddings are used to represent words in a multi-dimensional space, where words with similar meanings or contexts are closer to each other.
One common application of word embeddings is in autocomplete or predictive text features, which are commonly found in text input fields, messaging apps, and search engines. These features aim to predict the next word or phrase that a user is likely to type based on their previous input, and they can significantly improve the user experience by reducing typing time and errors.
There are several ways that word embeddings can be used to improve the accuracy of autocomplete or predictive text features:
- Contextual word prediction: Word embeddings capture the context in which words appear, so they can be used to predict the next word based on the words that come before it. For example, if a user types "I am going to the", the autocomplete feature might suggest "store" or "mall" as the next word, based on the context of the previous words. This can be especially useful for predicting words that might not be in the user's dictionary or are not commonly used.
- Personalization: Word embeddings can be trained on a user's personal data, such as their emails, messages, or social media posts, to create a personalized word prediction model. This can improve the accuracy of the autocomplete feature by taking into account the user's unique language patterns and preferences.
- Language modeling: Word embeddings can be used in conjunction with a language model to predict the likelihood of a word or phrase appearing given the previous words in the input. This can help the autocomplete feature to suggest more appropriate and relevant words, rather than just the most commonly used words.
- Spelling correction: Word embeddings can be used to correct spelling errors in the input text by suggesting the correct spelling based on the context of the surrounding words. This can be especially useful for users who are typing quickly or have a limited vocabulary.
- Sentiment analysis: Word embeddings can be used to analyze the sentiment of the input text, which can be useful for predicting the next word or phrase based on the overall tone of the conversation. For example, if the user is typing a positive message, the autocomplete feature might suggest more positive words.
In conclusion, word embeddings can significantly improve the accuracy of autocomplete or predictive text features by taking into account the context and meaning of the words, as well as the user's personal language patterns and preferences. By using word embeddings, autocomplete features can provide more relevant and appropriate predictions, leading to a better user experience.
How Do Word Embeddings Help with Language Translation or Localization for SEO Purposes?
Word embeddings are a way of representing words and their meanings in a way that can be easily understood by computers. They are used in a variety of natural language processing (NLP) tasks, including language translation and localization for SEO purposes.
One way that word embeddings help with language translation is by providing a common representation of words in different languages. In order to translate a word from one language to another, a machine learning model needs to understand the meaning of the word in both languages. Word embeddings can provide this understanding by representing words in a way that is language-agnostic. This means that a word embedding for a word in one language can be compared to a word embedding for the same word in another language, allowing the machine learning model to understand the meaning of the word in both languages.
Another way that word embeddings help with language translation is by providing context for words. In natural language, the meaning of a word can vary depending on the context in which it is used. For example, the word "bank" could refer to a financial institution, the edge of a river, or a series of stairs. Word embeddings can capture this context by representing words in relation to other words that commonly appear in the same context. This allows the machine learning model to understand the context in which a word is being used, and to choose the appropriate translation based on that context.
Word embeddings also help with localization for SEO purposes. Localization refers to the process of adapting a product or service to a specific country or region. This is important for SEO because search engines use algorithms that are specific to each country or region. For example, a search engine in the United States may prioritize different websites than a search engine in France.
Word embeddings can help with localization by allowing the machine learning model to understand the specific language and cultural context of each region. For example, a word embedding for the word "car" in the United States might be more closely related to words like "automobile" and "vehicle," while a word embedding for the same word in France might be more closely related to words like "voiture" and "automobile." This allows the machine learning model to understand the specific language and cultural context of each region, and to choose the appropriate translation based on that context.
Overall, word embeddings are an important tool for language translation and localization for SEO purposes. They allow machine learning models to understand the meanings of words in different languages, and to choose the appropriate translations based on the context in which those words are used. By using word embeddings, businesses can improve their SEO efforts by ensuring that their website content is accurately translated and localized for each specific region.
Can Word Embeddings Be Used to Identify and Analyze User Intent Behind Search Queries?
Word embeddings are a type of language processing technique that converts words into numerical vectors that can be understood and analyzed by a computer. These embeddings capture the context and meaning of words, allowing for more accurate analysis of language.
In the realm of search queries, word embeddings can be used to identify and analyze user intent behind these searches.
One way that word embeddings can be used to identify user intent is through the use of semantic search. Semantic search involves using algorithms to understand the meaning behind a search query and provide relevant results. Word embeddings can be used to analyze the context and meaning of the words in a search query, allowing the search algorithm to understand the user’s intended meaning and provide more accurate results.
For example, if a user searches for “best pizza near me,” the word embeddings can analyze the words “best,” “pizza,” and “near me” to understand that the user is looking for the best pizza restaurants in their local area. This allows the search algorithm to provide results based on the user’s intended meaning, rather than simply matching the words in the search query with websites or pages that contain those words.
Another way that word embeddings can be used to analyze user intent is through the use of sentiment analysis. Sentiment analysis involves using algorithms to understand the emotional content of language and determine whether it is positive, negative, or neutral. Word embeddings can be used to analyze the words in a search query to determine the user’s emotional state or intention.
For example, if a user searches for “I hate my job,” the word embeddings can analyze the words “hate” and “job” to understand that the user is feeling negative about their job. This allows the search algorithm to provide results that may be relevant to the user’s emotional state, such as job search websites or articles on how to improve job satisfaction.
Word embeddings can also be used to analyze user intent through the use of keyword analysis. Keyword analysis involves identifying the most important words or phrases in a search query and using them to understand the user’s intent. Word embeddings can be used to analyze the context and meaning of these keywords to determine the user’s intended meaning.
For example, if a user searches for “best car insurance for young drivers,” the word embeddings can analyze the words “best,” “car insurance,” and “young drivers” to understand that the user is looking for the best car insurance options for young drivers. This allows the search algorithm to provide results based on the user’s intended meaning, rather than simply matching the words in the search query with websites or pages that contain those words.
Overall, word embeddings can be used to identify and analyze user intent behind search queries by providing a more accurate understanding of the context and meaning of the words in the search query. This allows search algorithms to provide more relevant and accurate results, improving the user experience and helping users find the information they are looking for more quickly and easily.
How Do Word Embeddings Compare to Other Techniques Such as N-Gram Analysis or Bag-of-Words Model in Terms of SEO Effectiveness?
Word embeddings are a type of language processing technique that involves mapping words to a continuous vector space, with each dimension representing a specific semantic or syntactic feature.
This allows for the creation of a numerical representation of words that can be used in various natural language processing tasks, such as language translation, information retrieval, and text classification.
One of the main advantages of word embeddings is that they capture the context and meaning of words within a given corpus, rather than simply treating them as individual units. This is in contrast to techniques like n-gram analysis or the bag-of-words model, which focus on the frequency and occurrence of individual words or combinations of words within a document.
In terms of SEO effectiveness, word embeddings have several advantages over these other techniques. Firstly, they allow for a more nuanced understanding of the meaning and context of words within a document, which can be useful for determining the relevance and quality of a webpage. For example, a webpage that contains the word "apple" may be more relevant for the keyword "apple" if it is used in the context of a fruit, rather than a company or product. Word embeddings can capture this context and provide a more accurate representation of the content of a webpage.
Secondly, word embeddings can be useful for detecting synonyms and related words within a document, which can be useful for expanding the reach of a webpage to a wider audience. For example, if a webpage is optimized for the keyword "dog," but also contains the word "canine," a word embedding model may recognize the similarity between the two words and suggest targeting the keyword "canine" as well. This can be particularly useful for increasing the visibility of a webpage in search results, as it allows for targeting a wider range of related keywords.
In contrast, n-gram analysis and the bag-of-words model do not have the ability to capture the context or meaning of words within a document, and instead focus solely on the frequency and occurrence of individual words or combinations of words. This can make these techniques less effective at determining the relevance and quality of a webpage, as they do not take into account the meaning or context of the words used.
Furthermore, n-gram analysis and the bag-of-words model are less effective at detecting synonyms and related words within a document, as they do not have the ability to recognize the semantic relationships between words. This can limit the reach of a webpage, as it may only be optimized for a narrow set of specific keywords, rather than a wider range of related terms.
Overall, word embeddings offer several advantages over techniques like n-gram analysis and the bag-of-words model in terms of SEO effectiveness. They provide a more nuanced understanding of the meaning and context of words within a document, allowing for more accurate determination of relevance and quality. They also have the ability to detect synonyms and related words, which can expand the reach of a webpage and increase its visibility in search results. While these other techniques may still have some use in SEO, word embeddings offer a more comprehensive and effective approach for optimizing the content of a webpage.
How Market Brew Uses Word Embeddings
How Market Brew Uses Word Embeddings
Market Brew is a search engine model that utilizes word embeddings in several ways to improve its accuracy when modeling other search engines.
One of the main ways it uses word embeddings is through Market Brew's AI Overviews Visualizer, which leverages its model of Sentence-BERT to do word embeddings during its indexing process.
Word Embeddings are featured as one of the four distinct approaches to semantically classifying content, utilized in the model of Google's AI Overviews.
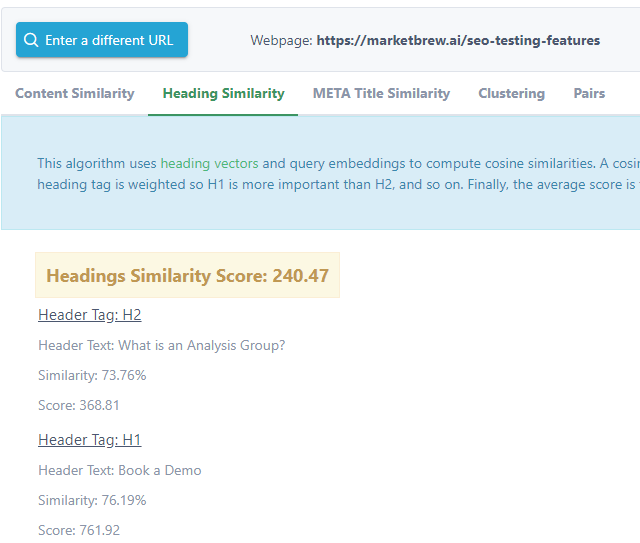
An practical example of the usage of embeddings is in modeled algorithms such as Google's Heading Vector algorithm.
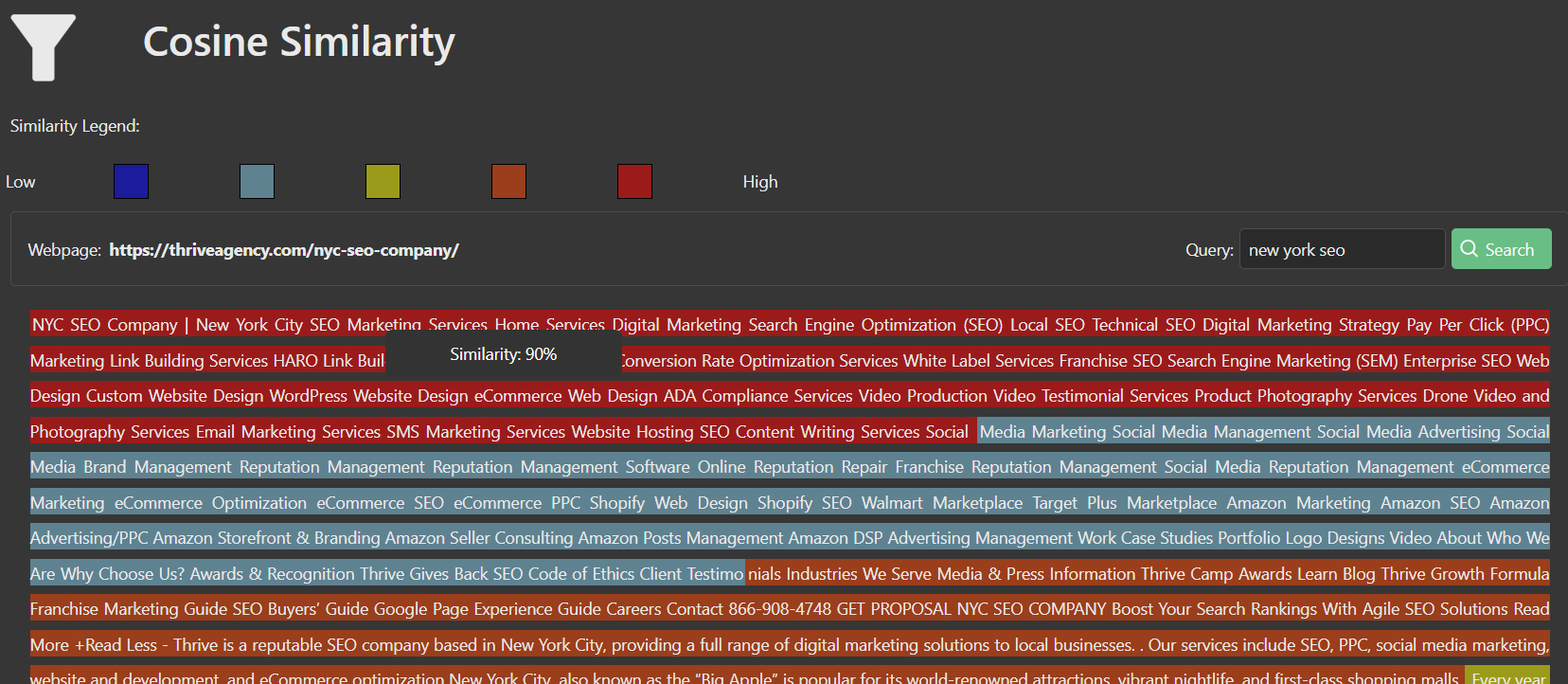
Throughout the Market Brew A/B Testing Platform, users will see the usage of embeddings.
Overall, the use of word embeddings in Market Brew's search engine models helps to improve the relevance and accuracy of search results by allowing the search engine to understand the meaning behind each word and the connections between different entities.
This helps to ensure that semantic and keyword based algorithms are more precisely calculated like the target search engine would, and this leads to higher correlating algorithms which give more accurate guidance.
You May Also Like:
Guides & Videos
Others
Effective Copywriting for SEO
Guides & Videos
Convolution Neural Networks in SEO
Guides & Videos
SEO Is Your Brand’s Online Reputation
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.