
The Search Engine's Semantic Algorithm Arc
Semantic analysis algorithms play a crucial role in understanding the meaning and context of textual data. This article explores the evolution of semantic algorithms, tracing their journey from traditional TF-IDF methods to more advanced techniques such as keyword density analysis, entity-based algorithms, and finally, embeddings and cosine similarities.
By examining each stage of this semantic algorithm arc, we uncover the challenges faced by earlier methods and the innovations that have led to more sophisticated approaches for capturing semantic meaning.
Through a comprehensive analysis, this article aims to provide insights into the progression of semantic analysis techniques and their implications for natural language processing tasks.
In the vast landscape of natural language processing (NLP), the ability to understand and interpret the meaning of text is a fundamental challenge. Semantic analysis algorithms serve as the backbone of NLP systems, enabling machines to comprehend human language and extract valuable insights from textual data. Over the years, the field of semantic analysis has witnessed a remarkable evolution, marked by the development of increasingly sophisticated algorithms designed to capture the nuanced semantics inherent in language.
The journey of semantic algorithms begins with the advent of TF-IDF (Term Frequency-Inverse Document Frequency), a cornerstone technique in information retrieval and text mining. TF-IDF assigns weights to terms based on their frequency in a document relative to their frequency across a corpus, allowing for the identification of key terms that are most representative of a document's content. While TF-IDF revolutionized the way documents are indexed and retrieved, its reliance on statistical metrics posed limitations in capturing the deeper semantic nuances of language.
As researchers sought to overcome the shortcomings of TF-IDF, the focus shifted towards techniques that could better capture semantic meaning. Keyword density analysis emerged as a prominent approach, aiming to identify the prevalence of specific keywords within a document and their distribution across its content. By analyzing keyword density, algorithms could infer the topical relevance of a document and its thematic focus. However, like TF-IDF, keyword density analysis struggled to capture the complex interplay of meaning and context inherent in natural language.
The next leap in semantic analysis came with the introduction of entity-based algorithms, which sought to model language understanding based on the relationships between entities within a knowledge graph. By leveraging structured knowledge representations, such as ontologies and taxonomies, entity-based algorithms could infer semantic connections between entities and discern the underlying semantics of textual data more effectively. This approach represented a significant advancement in semantic analysis, allowing algorithms to move beyond surface-level statistics and delve into the semantic fabric of language.
In recent years, the rise of word embeddings has reshaped the landscape of semantic analysis, offering a paradigm shift in how semantic meaning is represented and processed. Word embeddings, such as Word2Vec and GloVe and later BERT and ELMo, encode semantic relationships between words in dense vector spaces, capturing semantic similarity and semantic context more accurately than previous methods. Coupled with techniques like cosine similarity, which measures the angular similarity between vectors, word embeddings have enabled algorithms to perform a wide range of semantic tasks with unprecedented accuracy and efficiency.
In this article, we embark on a journey through the evolution of semantic analysis algorithms, tracing their trajectory from the foundational principles of TF-IDF to the cutting-edge techniques of word embeddings and cosine similarities. By exploring each stage of this semantic algorithm arc, we gain a deeper understanding of the challenges, innovations, and implications shaping the field of semantic analysis in modern NLP systems.
How Does the TF-IDF Algorithm Work and What Are Its Main Components?
Term Frequency-Inverse Document Frequency, commonly known as TF-IDF, is a cornerstone technique in information retrieval and text mining. It's a statistical measure that evaluates how important a word is to a document in a corpus, leveraging a balancing act between word frequency and document frequency that allows it to discriminate among words effectively.
The core idea behind TF-IDF is to weigh terms based not just on their frequency in a document, but also on their rarity across the whole corpus. This dual emphasis allows TF-IDF to distinguish important words by downgrading common words and uplifting rare words.
TF-IDF calculates a weight for each term (t) in a document (d), which increases proportionally with the number of times the term appears in the document but is offset by the frequency of the term in the corpus.
The TF-IDF algorithm comprises two main components: Term Frequency (TF) and Inverse Document Frequency (IDF).
Term Frequency (TF) is the raw count of a term in a document, which is often normalized to prevent a bias towards longer documents, which could have a higher occurrence of a particular term. The simplest form of TF is simply a count of the number of times a certain term appears in a specific document. However, in most contexts, TF is normalized by the total number of words in the document, resulting in a metric that represents the proportion of the calculated term to all terms in the document.
On the other hand, Inverse Document Frequency (IDF) is a measure of how common or rare a word is across the entire document set. Essentially, IDF downgrades those words that are too common across the corpus and are likely to carry less information. IDF is computed as the logarithm of the total number of documents in the corpus divided by the number of documents containing the term. The logarithmic scale ensures that the measure isn't skewed by very frequent or very rare terms.
In this way, TF-IDF assigns to terms high weights that are often used within specific documents, but rarely used across all documents. This makes TF-IDF effective in information retrieval systems, where the objective is to filter out the most relevant information or document based on specific search queries.
Another key aspect of the TF-IDF framework is the scalability it offers. As the size of the document set increases, TF-IDF can scale up remarkably well, making it an ideal technique for real-world applications where the volume of text data can be enormous.
While TF-IDF is a powerful method for word representation and quite effective for tasks such as information retrieval and text mining, it does have its limitations. The most notable limitation is perhaps the fact that TF-IDF only considers the raw frequencies of term occurrences while ignoring the contextual relations between words, which can lead to suboptimal understanding of the true semantics of a piece of text.
As such, techniques like TF-IDF often form only the initial steps of the semantic algorithm arc. The quest for algorithms that can capture richer and more nuanced semantic understanding of texts continues to drive advances in the field of natural language processing.
What Are the Limitations of TF-IDF Algorithms in Capturing Semantic Meaning?
Term Frequency-Inverse Document Frequency, commonly known as TF-IDF, is a fundamental technique in information retrieval and text mining. It quantifies the importance of words in a document with respect to a corpus.
Despite its wide application, TF-IDF has several limitations, particularly in capturing semantic meaning.
- TF-IDF is based on the bag-of-words (BoW) model, which treats text as an unordered collection of words. This model disregards sentence structure, order of words, and context, thereby causing a significant loss in semantic information. For instance, the sentences “The cat chases the mouse” and “The mouse chases the cat” have very different meanings, but are treated identically under the BoW model because they contain the same words.
- While the IDF component of TF-IDF reduces the weights of common words present in many documents, it fails to discern nuanced differences in word usage across different contexts. For example, the word 'apple' may refer to the tech company in a business article or the fruit in a recipe, but TF-IDF treats both occurrences as the same. This inability to distinguish polysemy (multiple meanings of a word) is a significant bottleneck in capturing semantic meaning.
- TF-IDF cannot capture the semantic relationships or similarities between words. For instance, synonyms like 'buy and 'purchase' or semantically related words like 'hospital' and 'doctor' are treated as distinct by TF-IDF. It lacks the ability to understand that different words can hold similar meanings or be part of a related concept. This limitation hampers the algorithm's effectiveness in tasks like semantic search or document clustering, where the understanding of semantic relationships is vital.
- TF-IDF treats documents as isolated entities and does not consider the meaning captured through the interrelation of documents in a corpus. It focuses on term frequencies within individual documents and overall corpus, neglecting the broader semantic landscape formed by the relationships between multiple documents.
- TF-IDF struggles with handling negation and modifier words that significantly alter the meaning of a sentence. For instance, ‘not good’ and ‘very good’ have completely different sentiments, but due to the disregard for word order and interrelation, TF-IDF provides no mechanism to capture these semantic dimensions.
While TF-IDF provides a robust method for scoring the importance of words in a document, it fails to discern the contextual and structural facets of language that are crucial to capturing semantic meaning. Its reliance on statistical measure of word frequencies and disregard for syntactic and semantic relationships mark its major limitations. Therefore, newer algorithmic approaches are needed that can better capture the intricacies of semantic meaning in language, progressing beyond the limitations of techniques like TF-IDF.
How Does Keyword Density Play a Role in Semantic Analysis and How Does It Differ from TF-IDF?
Keyword density has been a performance enhancer in the world of search engine optimization and content creation. It refers to the percentage of times a keyword or key phrase appears in web content as compared to the total number of words within that content.
The primary goal of keyword density algorithms is to ensure that content remains relevant to its subject matter.
Unlike TF-IDF, which is concerned with individual word frequencies in comparison to their occurrence in a set of documents, keyword density puts a higher emphasis on the occurrence of those selected keywords in relation to the document’s length. Its primary focus is on how the distribution and frequency of keywords throughout a piece of content could indicate its relevance to a specific topic or subject. This method assumes that if a term or phrase appears more frequently, then the document is probably more related to that term.
However, the advancement in semantic analysis has shown that relying solely on the frequency of a word may not always be indicative of the context or true meaning of the content. For instance, an article on lions that frequently uses the term "pride" may not necessarily imply content relevancy to the topic of self-esteem or narcissism. But an algorithm relying simply on keyword density could potentially misinterpret this.
On the other hand, TF-IDF provides visibility into the importance of a word by considering not only its frequency in a document but also how frequently it appears across multiple documents. This allows it to identify words that are unique to a document, which is often a more meaningful way of understanding the content.
Keyword density and TF-IDF are indeed different but they have proven to provide immense value in semantic analysis and natural language processing tasks. While TF-IDF augments the process by providing weight to terms that appear less frequently across a pool of documents, keyword density highlights topic relevance based on how frequently a keyword is used within a single document.
Ultimately, though valuable, neither of these methods can fully capture the nuanced context and complex semantic relationships of natural language. As a result, subsequent semantic analysis techniques have progressed to more complex methods, specifically focusing on understanding and leveraging these complex relationships, such as entity-based algorithms or word embeddings.
So while considering keyword density and TF-IDF within an algorithm's strategy might be beneficial for certain tasks, the inherent limitations of these methods have led researchers and practitioners to explore more advanced techniques for digging deeper into the semantic goldmine offered by human language. The dynamic evolution along the semantic algorithm arc thus represents the constant strive to mirror human language comprehension as closely as possible.
What Are the Advantages and Disadvantages of Using Keyword Density Algorithms Compared to TF-IDF?
Keyword density algorithms and TF-IDF (Term Frequency-Inverse Document Frequency) are both prominent techniques in semantic analysis and information retrieval. However, they each come with unique advantages and disadvantages, which make them specifically suited to certain use cases.
Keyword density-based algorithms focus on identifying how often specific keywords crop up within a given text. By working out the percentage of times a keyword appears compared to the total number of words in the piece, the algorithm can gauge the relevance or significance of that keyword in the context of the document. Moreover, keyword density algorithms are generally simple and fast, making them a viable choice for quick scanning of lengthy documents.
Additionally, keyword density algorithms are extremely straightforward and intuitive to use, making them easily leveraged by SEO specialists for optimizing web content. By understanding which keywords are appearing most frequently, content creators can optimize their articles or blogs to rank well in search engine results.
However, keyword density algorithms come with certain limitations. They are primarily based on the raw frequency of words and might not capture the overall sematic relevance of a term within a large text corpus. A keyword may have high density in a document but may be generic or common across the entire corpus, reducing its discriminatory power. Moreover, keyword density algorithms do not consider the semantic relationship between words and can be manipulated easily with keyword stuffing, potentially leading to poor user experience.
On the contrary, TF-IDF, a popular weighting scheme in information retrieval, can address some of the drawbacks of keyword density algorithms. TF-IDF assigns a weight to each term to signify its importance not just in a document, but across the entire document corpus. Unlike keyword density, it calculates the term frequency (TF), similar to keyword density but juxtaposed with inverse document frequency (IDF), a measure of how frequently the term occurs across all documents. Consequently, TF-IDF can distinguish the significance of rare terms across the corpus giving a more balanced importance to descriptive terms that offer more semantic significance.
However, the TF-IDF model too is not without flaws. One of the critical criticisms is it assumes all terms are independent and does not capture the context or the sequence of the words. Moreover, TF-IDF shares a common drawback with keyword density: it neglects the semantic relationships between words. Though it can better highlight important terms in a document, it still fails to capture the intricacies of natural language, such as polysemy or homonymy.
While keyword density and TF-IDF algorithms provide foundational techniques for semantic analysis and are easy to implement, they ultimately fall short in capturing the complexity and richness of natural language. However, when combined with more advanced techniques, such as entity-based algorithms and word embeddings, they can still offer valuable inputs for holistic semantic analysis.
What Are Entity-Based Algorithms in Semantic Analysis, and How Do They Utilize Knowledge Graphs?
Entity-based semantic analysis algorithms signify a major milestone in the progression of semantic intelligence in natural language processing systems. These algorithms bridge the gap between statistical methods and deeper semantic understanding, leveraging structured knowledge representations to decipher complex language patterns.
In essence, entity-based semantic analysis algorithms are designed to model, map, and analyze the relationships between distinct entities within a body of text. Entities could range from individuals, organizations, locations, events, to more abstract concepts such as dates or phrases. In recognizing these entities, the algorithms can identify meaningful connections, infer context, and draw insights based on the interplay between them.
Central to the workings of entity-based algorithms are knowledge graphs - interconnected graphical depictions of entities and their relationships. Each node in a knowledge graph represents a distinct entity, while the edges denote the relationships or interactions between nodes. The expansive and deeply interconnected nature of knowledge graphs allows these algorithms to understand and analyze a wide variety of relationships, capture nuances, and predict meaning from these relationships.
Knowledge graphs serve a pivotal role in entity-based semantic analysis by offering a rich, structured knowledge base that the algorithms can tap into. The data represented in a knowledge graph mimics the way humans understand and navigate the world, providing contextual links and semantic information that aid in discerning meaning. By mapping entities to their corresponding nodes in a knowledge graph and going beyond immediate entity relationships, these algorithms can infer deeper semantic connections that are not entirely obvious from the textual data itself.
For instance, consider the sentence "Apple launches the new iPhone in San Francisco." Entity-based algorithms will recognize "Apple," "iPhone," and "San Francisco" as entities. Using a knowledge graph, the algorithms can understand that 'Apple' is a technology company, 'iPhone' is a product of 'Apple,' and 'San Francisco' is a city where tech companies like 'Apple' often conduct product launches. Such complexity and contextual understanding of entities wouldn’t be possible using traditional TF-IDF or keyword density analysis.
Moreover, entity-based algorithms can contextualize and disambiguate entities further using a knowledge graph's content. For example, in the sentence "Mercury will be at its peak visibility tonight," referencing the planet, not the element or the automobile maker. By leveraging knowledge graphs, entity-based algorithms can reliably make the correct identification.
The true power of entity-based semantic analysis algorithms lies in their ability to understand and interpret language in a way that's closer to human cognition, leveraging the rich contextual information embedded in knowledge graphs. Through this, they are capable of capturing the essence and the inherent connections in textual data, bringing us one step closer to mimicking the complex process of human language understanding. While challenges persist in their scalability and adaptability to evolving language use, entity-based algorithms signify a fundamental shift in the realm of semantic analysis, paving the way for more nuanced and contextually aware natural language processing.
Can You Explain the Relationship Between Entities, Knowledge Graphs, and Semantic Understanding in Algorithms?
Addressing the question of the relationship between entities, knowledge graphs, and semantic understanding in algorithms requires a comprehensive understanding of how these individual components interact with each other in the global frontier of natural language processing (NLP).
Entities, in the context of NLP, refer to recognizable and distinct units in text which can vary from named entities like people, organizations, and locations to numerical entities such as dates, percentages, and monetary values. Entities are the building blocks of language and act as key anchors around which semantic context and meaning revolve. The understanding of these entities hence forms the basis of semantic understanding in NLP algorithms.
Meanwhile, knowledge graphs, often visualized as vast networks of nodes and edges representing entities and their interrelationships, provide a structured way to organize and represent knowledge. They map how entities relate to one another in a multi-relational manner which mirrors our own human understanding of the world. Knowledge graphs encode not just isolated facts but the intricate interweaving of entities in context, allowing for semantic inferences and a richer understanding of the entity relationships found in unstructured text.
The relationship between entities and knowledge graphs is an intricately woven one. The entities make up the nodes of the knowledge graph while the edges between these nodes represent the contextual and semantic relationships that exist between the entities. For instance, in a knowledge graph, Barack Obama (Entity 1) and United States (Entity 2) might be linked by the relationship "was the president of" thus encapsulating the semantic relationship between these two entities.
The incorporation of these knowledge graphs into semantic algorithms powers them with the ability to harness this network of interconnected entities to derive meaningful gleanings from raw text. It allows an algorithm to understand the nuanced semantics of an entity by situating it in the larger architectural context of related entities.
For example, when deciphering the meaning of the sentence, "Apple released a new product", semantic algorithms which utilize knowledge graphs can distinguish between Apple, the technology company, and apple, the fruit, by examining the context and the interactions of the "Apple" entity within the knowledge graph.
Furthermore, this same concept of entity and relations also forms the fundamental basis for advanced NLP tasks like entity linking, that involves associating entities in the text with their corresponding entries in the knowledge graph.
Therefore, by mapping out entities and their intricate relationships in the form of a knowledge graph, we can equip algorithms with a degree of semantic understanding that not only mirrors human comprehension but also transcends the limitations of syntax and surface-level analysis to derive true underlying context and meaning.
In essence, while entities act as the nuts and bolts of semantic understanding, knowledge graphs operate as the blueprint that determines how these pieces fit together into a meaningful whole. The fusion of entities, knowledge graphs, and semantic understanding in algorithms thus signifies a meaningful leap towards achieving rich, nuanced, and anthropomorphic levels of comprehension in NLP systems.
What Advancements Have Been Made in Entity-Based Algorithms in Recent Years, and How Do They Improve Semantic Analysis?
Entity-based algorithms form the backbone of many natural language processing systems, significantly advancing our understanding and analysis of semantics in recent years. Their innovation lies in the use of entities with associated metadata instead of simple word systems, moving beyond the limitations of term frequency count and simple keyword analysis.
The evolution of entity-based semantic algorithms – powered by advanced machine learning and knowledge graphs – has made it possible to decode complex content by examining relationships and dependencies between different elements in a text.
One of the most significant advancements in recent years is the capacity of entity-based algorithms to leverage the power of knowledge graphs. Knowledge graphs, such as Google's Knowledge Graph, contain well-structured, interlinked information and store it in graph databases, which drive more dynamic and context-appropriate responses to queries. Knowledge graphs capture rich semantic relationships, expressing the context, attributes, and interrelation of different entities, thus making this understanding accessible to entity-based algorithms that delve into the depths of semantic analysis.
In contrast to traditional keyword-centric algorithms, entity-based algorithms can infer the meaning of a word based on defined entities in a knowledge graph, solving the ambiguity problem inherent in natural language. For example, 'Apple' can mean a fruit, a giant tech company, or a record company. Semantic algorithms can distinguish between these meanings based on knowledge provided by the graph.
Another recent advancement in entity-based algorithms is the rise of 'named entity recognition' (NER). NER is a sub-process of information extraction that seeks to locate and classify named entities in text into predefined categories. By identifying the entities in a sentence or paragraph, these algorithms can better understand the context and intent behind a piece of text.
Synonym recognition is another noteworthy improvement in the sphere of entity-based algorithms. Modern semantic algorithms can identify the connection between different terms that signify identical or closely related entities. This ability enhances the dimensionality of contextual understanding and paves the way for more accurate semantic analysis.
Moreover, the application of deep learning techniques, such as recurrent neural networks and transformer-based architectures like Google's BERT, has opened new horizons for entity-based semantic analysis. These often utilize pre-trained embeddings and models which are capable of embedding context in analyzing linguistic units, thus providing a more nuanced understanding of entities than ever before.
Entities' capability of being connected to one another in intricately woven knowledge graphs makes them vector targets for representation learning. For instance, TransE is a method that models relationships by interpreting them as translations operating on the low-dimensional embeddings of entities.
The advancements in entity-based algorithms have brought about a revolution in semantic analysis. The shift from simple term-frequency-based models to intricate entity-based models, augmented by knowledge graphs and deep learning, marks a tremendous improvement. The complexity of natural language can be better analyzed, the ambiguity of text more accurately deciphered, and the understanding of context significantly enriched. As a result, our interaction with technology has become more nuanced, personalized, and efficient.
How Do Word Embeddings Contribute to Semantic Analysis, and What Are Some Popular Techniques Used for Generating Embeddings?
Word embeddings are the modern answer to the question of proper text representation in computational linguistics and natural language processing. They are fundamental to many NLP tasks as they offer a robust method of capturing semantic and syntactic relations between words in a vector space.
By modeling words as real-valued vectors, word embeddings allow machines to understand words in relation to each other, thereby enabling effective semantic analysis.
Unlike traditional text representation approaches such as Bag of Words (BoW) or TF-IDF, which treat words as isolated units with no inherent contexts, word embeddings capture the subtleties and complexities of language. They achieve this by positioning similar words close to each other in the high-dimensional vector space. A popular example of this is the word "king" being in close proximity to the word "queen," mirroring their interrelated meanings in the semantic space.
Word embeddings are generated via unsupervised learning on a large corpora of text. Two of the most well-known techniques for creating word embeddings are Word2Vec and GloVe.
Word2Vec, developed by researchers at Google, represents words in a dense vector space that maintains semantic relationships. It operates under two main architectures: Continuous Bag of Words (CBOW) and Skip-gram. CBOW predicts a target word from its context, while Skip-gram does the contrary; it predicts context words from a target word. Through this learning process, Word2Vec achieves meaningful semantic transformations. For instance, adding the vector for 'man' to the vector for 'queen,' and subtracting the vector for 'woman,' results in a vector that is similar to 'king.'
GloVe (Global Vectors for Word Representation), developed by Stanford University researchers, takes a different tack. It constructs an explicit word-context or word-word co-occurrence matrix using statistics across the whole text corpus. Essentially, it attempts to directly learn the vectors such that their dot product equals the logarithm of the words’ probability of co-occurrence. GloVe leverages both global statistical information (through the co-occurrence matrix) and local semantic relations (through dimensionality reduction), thereby packing more contextual information into the resultant vectors.
More recently, methods like ELMo (Embeddings from Language Models), BERT (Bidirectional Encoder Representations from Transformers), and GPT (Generative Pre-training Transformer) have pioneered context-dependent word embeddings. These techniques generate embeddings based on the particular context within which a word appears, adding another layer of sophistication to the understanding of semantics.
Word embeddings fundamentally contribute to semantic analysis by providing a nuanced and context-sensitive understanding of language. Techniques like Word2Vec and GloVe have paved the way for more complex algorithms that continuously improve our ability to analyze semantics and decode the complex tapestry of human language. As we continue to develop these advanced tools and resources, our understanding and processing of linguistic data consequently evolve, opening new frontiers in natural language processing and semantic analysis.
What Is Cosine Similarity, and How Is It Used in Conjunction with Word Embeddings for Semantic Similarity Tasks?
Cosine similarity is a metric used in the field of machine learning to measure how similar two vectors are, regardless of their size. In the realm of natural language processing (NLP), this mathematical concept becomes a critical measure of similarity in semantic tasks, specifically when it intertwines with the concept of word embeddings.
Word embeddings are a type of word representation that captures numerous dimensions of a word’s meaning and translates the semantic relationships between words into mathematical form. They cluster words of similar meaning based on the context of their usage within documents, representing them as vectors in a multi-dimensional space.
Here is where cosine similarity comes into the picture. Cosine similarity gauges the cosine of the angle between two vectors to determine how close they are to each other. To boil it down to simpler terms, if the vectors are closer in direction, the cosine value will be close to one, indicating a high level of similarity. Conversely, if the vectors have diverging paths or are orthogonal, the cosine value tends towards zero, signifying lower degrees of similarity or even complete divergence.
In essence, the cosine similarity allows us to convert the semantic relationships established by word embeddings into measurable entities, something vital for semantic similarity tasks in NLP.
Using cosine similarity with word embeddings for semantic similarity tasks has indeed revolutionized many aspects of NLP. It allows algorithms to assess and quantify the level of semantic similarity between words or documents, hence facilitating several tasks such as document clustering, text classification, recommendation systems, sentiment analysis, and so forth.
For instance, in document clustering, cosine similarity can help group together documents that discuss similar topics based on the vectors of the words they contain. This similarity assessment can aid information retrieval systems deliver more precise results, as it enables them to understand that a document discussing "dogs", would be closely related to another discussing "puppies" or "canines".
Moreover, in analyzing sentiments, understanding the semantic similarity between words can also be crucial. A negative comment might use a diverse set of words to express dissatisfaction, and having a metric to measure the semantic similarity can help classify these various comments accurately into the intended sentiment group.
It is also important to note that while cosine similarity provides a powerful mechanism to assess semantic similarity, like any other metric, it has its own limitations and is most effective when paired with other NLP techniques for a more comprehensive analysis.
Cosine similarity, when paired with word embeddings, provides a robust way to measure semantic similarity, deeply enhancing the capabilities of NLP. Through this, we can accomplish more nuanced tasks in machine learning and AI, such as thematic classification, sentiment analysis, and recommendation systems, contributing significantly to a machine’s comprehension of language and semantics.
How Do Modern Semantic Algorithms Combine Various Techniques Such as Embeddings, Knowledge Graphs, and Cosine Similarities to Achieve More Accurate Semantic Understanding?
Understanding human language is one of the biggest challenges that machines face today. Machine learning and artificial intelligence have unlocked numerous possibilities, significantly enhancing the capability of computers to comprehend textual data, and modern semantic algorithms have been central to these advancements.
These algorithms have continually evolved to embrace a convergence of several techniques that work in unison to deliver more accurate semantic understanding, the key components being embeddings, knowledge graphs, and cosine similarities.
Starting with embeddings - in contrast to the traditional bag-of-words or TF-IDF models, which represent words individually, ignoring contextual relationships, word embeddings capture the semantic correlation between words. Word embedding models such as Word2Vec or GloVe represent words in multidimensional spaces where the geometric relations (angles and distances) between word vectors mirror their semantic relationships. In other words, similar words reside close to each other in this vector space, and the context of a word can be gauged from its surrounding words. This delivers a richer and more nuanced understanding of language semantics.
Knowledge graphs, on the other hand, offer a structured view of information. They are the relational graphs that represent entities as nodes and their relations as edges. Google’s Knowledge Graph is a prime example that has transformed the way search algorithms understand and deliver knowledge. In addition to assigning importance to words, knowledge graphs account for the relationships and interconnectedness between entities, providing a more holistic understanding of language semantics. They make it possible for algorithms to capture the world's complexity by building connections between entities based on distinct types of relationships, such as categorical or hierarchical links.
Lastly, cosine similarity, used in tandem with word embeddings, enhances the semantic understanding by quantifying the similarity between different pieces of text based on the angle between their word vectors. Regardless of the length of the document, the cosine similarity can give an accurate measure of how closely they are semantically related. This measurement is crucial when it comes to tasks like information retrieval, document clustering, or text classification where determining the semantic similarity between texts forms the base of analysis.
Modern semantic algorithms therefore combine these diverse techniques to gain a deep and comprehensive understanding of language semantics. They use embeddings to translate words and their associations into a form that machines can comprehend; they use knowledge graphs to understand the contextual and relational aspects of entities; and they use cosine similarity to measure the commonalities and differences between pieces of text to gain an understanding of their relative meanings in relation to each other.
Importantly, the combination of these techniques allows modern semantic algorithms to not just 'read' text but 'understand' it, scaling the complex semantic landscape of human language. The coherence and strength of this combination continually power advances in machine learning and AI, getting us closer to achieving machine understanding of human language on par with human comprehension.
The Hidden Recipe of Semantic Algorithms
Search engines like Google are incredibly complex systems that seamlessly blend multiple semantic algorithms to provide the most relevant and accurate results to a user's query. It's a tailor-made mix, with modern search engines interacting with different semantic algorithms like a symphonic conductor, blending them harmoniously to extract the most meaningful symphony of results.
This recipe of algorithms is adjusted for each SERP with a ‘bias/weight setting’ by supervised machine learning.
This starts by asking humans to filter websites and pages based on the Quality Rater Guidelines, which in turn drives the labeling mechanism during the machine learning process. Based on the desired results, the balance of these algorithms is weighted, which adjusts their prominence in the mix according to search engine’s objective: results that depict the filtering suggestions of the Quality Raters.
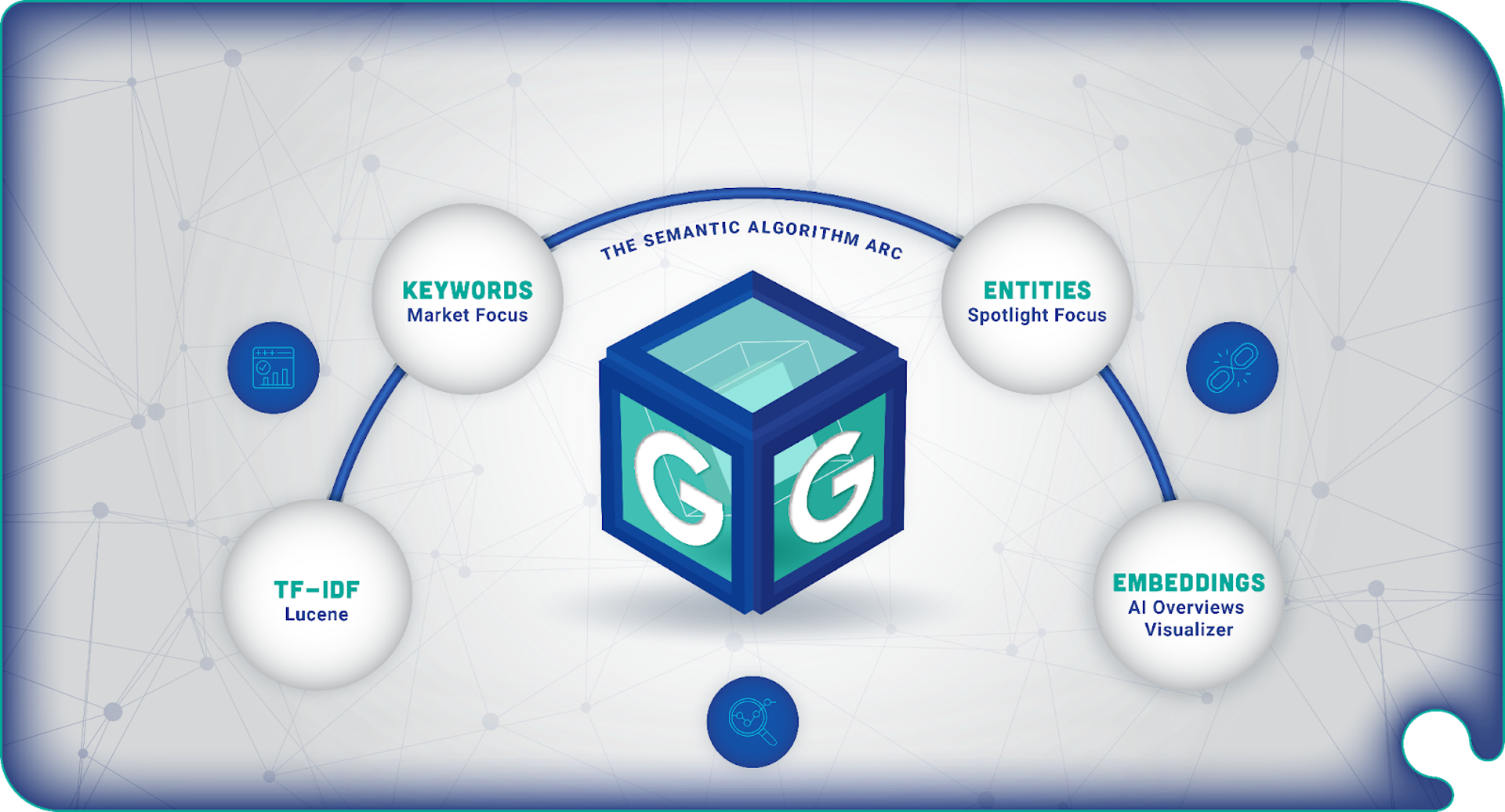
There exists four distinct semantic approaches that are modeled inside of Market Brew, and it appears that Google biases a different recipe of these four algorithms based on different search intent.
In Market Brew, the following four semantic algorithms are modeled:
- TF-IDF algorithm: modeled using the Lucene Query Parser.
- Keyword Density Analysis: modeled by the Market Focus algorithm,
- Entities and knowledge graph-based algorithms: modeled by Spotlight Focus, an entity-based algorithm that uses topic clusters and a knowledge graph derived from WikiData.
- Word embeddings and cosine similarities: modeled throughout the search engine model by embeddings and cosine similarities, and illustrated in our free tool the AI Overviews Visualizer.
The screenshot above is an example of how Market Brew works:
- Advanced visualizations of the reduced problem set are created.
- The team then injects these proposed algorithms into the testing model to see which ones correlate better.
- Those algorithms are published to the public list of modeled algorithms inside of Market Brew, and users can now take advantage of the comparison feature of Market Brew to find which landing page scores the best for this algorithm, for any given SERP.
The beauty of a search engine modeling approach is that users can see exactly what the recipe of these four semantic algorithms are, given the user's query and intent.
Depicted above is the ‘Semantic Algorithm Arc’, signifying the journey from TF-IDF to keywords to entities to embeddings.
The arc is like a tuning spectrum where each semantic algorithm's weight relies on the nature and context of the query, where the search engines act as a maestro, adjusting the intensity and prominence of each.
Market Brew is a mechanism to solve for this relative algorithm weighting for each SERP.
Once a calibrated control group is created, called a Ranking Blueprint, users can simulate the impact of changes to their target page and have the model predict the changes in SERP.
As a search engine modeling technology, Market Brew takes you behind the orchestra, giving you insights into each element of the algorithmic ensemble, helping you understand how the search engine brings them together harmoniously in its unique symphony.
Ready to Take Control of Your SEO?
See how Market Brew's predictive SEO models and expert team can unlock new opportunities for your site. Get tailored insights on how we can help your business rise above the competition.
Schedule a demonstration today via our Menu Button and Contact Form to discover how we engineer SEO success.
You May Also Like:
Guides & Videos
CSS and Stylesheets Improve SEO Performance
Guides & Videos
Others
Lemmatizer and Stemming in SEO
Guides & Videos
SEO Link Flow Analysis Essentials
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.