
The Basics Of Vector Space Models For SEO
Vector space models have become a widely used technique for improving the relevance and accuracy of search results in search engine optimization (SEO).
In this article, we explore the basics of vector space models and how they relate to SEO, including common techniques and the role of context and semantics.
We also discuss how vector space models handle synonyms, variations in language, and misspellings, as well as their ability to optimize the ranking of images and other multimedia.
Finally, we compare vector space models to other techniques for optimizing search results, such as machine learning and artificial intelligence.
The search landscape is constantly evolving, with users increasingly relying on search engines to find information, products, and services online.
As a result, search engine optimization (SEO) has become an essential part of the digital marketing mix, with businesses and organizations striving to improve the ranking of their websites and other digital assets in search results.
One technique that has become increasingly popular in SEO is the use of vector space models.
In this article, we will delve into the basics of vector space models and how they relate to SEO, as well as discussing the various techniques and considerations involved in their use. We will also compare vector space models to other approaches for optimizing search results, such as machine learning and artificial intelligence.
What Is A Vector Space Model And How Does It Relate To Search Engine Optimization (SEO)?
A vector space model is a mathematical representation of a set of documents or other items as points in a multi-dimensional space. In the context of search engine optimization (SEO), a vector space model can be used to represent a collection of documents or web pages in terms of the words they contain, with each dimension of the space representing a different word.
The distance between two points in the space can then be used to measure the similarity between the documents they represent.
One common use of vector space models in SEO is to represent the content of a website or a set of web pages in order to identify the most important or relevant words and phrases for a particular topic. This can help search engines determine the relevance of a web page to a particular search query, and rank it accordingly in search results. Some major semantic algorithms like Sentence-BERT use vector space models.
To create a vector space model for a set of documents, the first step is to identify the unique words that appear in the documents, and create a vector for each document that represents the frequency of each word in that document. The resulting vectors can then be compared to determine the similarity between the documents.
For example, consider a set of documents that all relate to the topic of "seo." The vector space model for these documents might include dimensions for words like "search," "engine," "optimization," and "ranking," among others. The values of these dimensions for a particular document would represent the frequency with which each of these words appears in that document.
One way to measure the similarity between two documents in the vector space model is to calculate the cosine of the angle between their vectors. This is done by taking the dot product of the vectors and dividing it by the product of the magnitudes of the vectors. The resulting value ranges from -1 to 1, with values closer to 1 indicating a higher degree of similarity and values closer to -1 indicating a lower degree of similarity.
In addition to measuring the similarity between documents, vector space models can also be used to identify the most important words or phrases for a particular topic. This can be done by analyzing the vectors for a set of documents and identifying the dimensions that have the highest values. These dimensions are likely to correspond to words or phrases that are most relevant to the topic, and can be used to optimize the content of a website or web page for search engines.
Overall, vector space models are a useful tool for search engine optimization because they allow for the mathematical representation and analysis of the content of a website or set of web pages. By identifying the most important words and phrases for a particular topic and optimizing the content of a website accordingly, it is possible to improve the ranking of a website in search results and increase its visibility to potential customers.
How Do Vector Space Models Help Improve The Relevance And Accuracy Of Search Results?
Vector space models (VSMs) are a mathematical representation of documents and queries used in information retrieval systems such as search engines.
They are based on the idea that words and documents can be represented as vectors in a multi-dimensional space, where the dimensions correspond to the words in the vocabulary of the documents being analyzed.
By representing documents and queries as vectors, it is possible to use mathematical operations to measure the similarity between them and to rank documents based on their relevance to a given query.
One of the main ways in which VSMs help improve the relevance and accuracy of search results is by taking into account the context in which words appear. In traditional search engines, a query is typically matched to documents based on the presence of individual keywords, regardless of how those keywords are used within the context of the document. This can lead to poor results, as a document may be relevant to a query even if it does not contain all of the query's keywords.
VSMs address this issue by considering the relationships between words in a document, rather than just their individual presence. For example, a VSM might assign higher weights to words that appear frequently in a document, or to words that appear in close proximity to each other. This allows the VSM to better capture the meaning and context of the document, and to more accurately match it to relevant queries.
Another way in which VSMs help improve search results is by allowing for the incorporation of synonyms and related terms. Traditional search engines often struggle to match queries to documents that use different words to convey the same meaning. For example, a query for "car" might not match a document that uses the word "automobile" to refer to the same thing.
VSMs can address this issue by representing synonyms and related terms as vectors that are close to each other in the vector space. This allows the VSM to match queries to documents that use different words to convey the same meaning, improving the relevance and accuracy of the search results.
VSMs also allow for the incorporation of user feedback and preferences into the search process. In many search engines, users can provide feedback on the relevance of search results by clicking on certain documents or marking them as helpful or not helpful. This feedback can be used to fine-tune the VSM, adjusting the weights of different words and documents to better match user preferences.
Overall, vector space models are a powerful tool for improving the relevance and accuracy of search results. By considering the context in which words appear, allowing for the incorporation of synonyms and related terms, and incorporating user feedback, VSMs are able to more accurately match queries to relevant documents, resulting in better search experiences for users.
What Are Some Common Techniques Used In Vector Space Models For SEO?
Vector space models are a type of mathematical model used in search engine optimization (SEO) to analyze the relevance of a particular website or webpage to a specific search query.
These models use vectors, or numerical representations of text, to compare the similarity between different documents and determine their relevance to a given search query.
There are several common techniques used in vector space models for SEO, including term frequency-inverse document frequency (TF-IDF), cosine similarity, and Latent Semantic Indexing (LSI).
One of the most widely used techniques in vector space models for SEO is term frequency-inverse document frequency (TF-IDF). This technique measures the importance of a particular word or phrase within a document by calculating its frequency within that document and comparing it to the frequency of the same word or phrase in other documents within a given collection. For example, if a particular word appears frequently in a document but rarely in other documents, it is considered more important and will be given a higher weight in the vector space model. This technique is useful for identifying key terms and phrases that are relevant to a particular search query and ranking webpages based on their relevance to those terms.
Another common technique used in vector space models for SEO is cosine similarity. This technique measures the similarity between two documents by calculating the cosine of the angle between their vectors in the vector space. A higher cosine similarity indicates that the documents are more similar, while a lower cosine similarity indicates that the documents are less similar. This technique is useful for identifying similar documents and grouping them together, which can help improve the accuracy and relevance of search results.
Latent Semantic Indexing (LSI) is another technique used in vector space models for SEO. This technique analyzes the relationships between words and phrases within a document and identifies hidden patterns or themes that may not be immediately apparent. For example, the words "apple," "fruit," and "juice" may all be related to the concept of "apple juice," even though the phrase "apple juice" does not appear in the document. By identifying these hidden patterns, LSI can help improve the accuracy and relevance of search results by ranking webpages based on the underlying themes or concepts they cover.
Other common techniques used in vector space models for SEO include singular value decomposition (SVD), which is used to reduce the dimensionality of a document vector and make it easier to analyze, and clustering, which is used to group similar documents together and improve the accuracy of search results.
In addition to these techniques, vector space models for SEO also often incorporate various algorithms and machine learning techniques to further improve the accuracy and relevance of search results. For example, natural language processing (NLP) algorithms may be used to analyze the structure and meaning of text, while machine learning algorithms such as decision trees and neural networks may be used to analyze and classify documents based on their content and relevance to a particular search query.
Overall, vector space models are an important tool in SEO, providing a way to analyze the relevance of webpages to specific search queries and improve the accuracy and relevance of search results. By using techniques such as TF-IDF, cosine similarity, and LSI, as well as various algorithms and machine learning techniques, vector space models help ensure that users are able to find the most relevant and useful information when searching online.
How Do Vector Space Models Take Into Account The Context And Semantics Of Search Queries And Documents?
Vector space models are a type of mathematical model used in information retrieval and natural language processing to represent text documents and search queries as numerical vectors in a multi-dimensional space.
These models take into account the context and semantics of the search queries and documents by using a variety of techniques to extract and encode important features and relationships between the words and concepts within them.
One way vector space models consider context and semantics is through the use of term frequency-inverse document frequency (TF-IDF) weighting.
This technique assigns higher weights to terms that are more important or relevant to a particular document or query, based on how frequently they appear within the document or query compared to other documents in the collection.
For example, if the term "cancer" appears multiple times in a document about medical research, it would be given a higher weight than if it only appeared once in a document about fashion. This helps the model understand the context and meaning of the document or query and retrieve relevant results.
Another technique used in vector space models is stemming, which involves reducing words to their root form so that variations of the same word are treated as the same term. For example, "run," "ran," and "running" would all be stemmed to the root form "run." This helps the model understand the meaning of a query or document and retrieve relevant results, as it can see that these words are related to one another and have a common meaning.
Vector space models also often use stop words, which are common words that are typically ignored or removed from the text during the processing stage. These words, such as "the," "a," and "an," do not contribute much meaning to the context or semantics of the text and can often be removed without affecting the overall meaning. By removing these words, the model can focus on the more important terms and better understand the meaning of the text.
In addition, vector space models may use synonyms and related terms to help understand the context and semantics of a query or document. For example, if a user searches for "car," the model may also consider related terms such as "automobile" or "vehicle" to retrieve relevant results. This helps the model understand the broader context and meaning of the query, rather than just focusing on the specific term "car."
Finally, vector space models may also use techniques such as latent semantic indexing (LSI) and latent Dirichlet allocation (LDA) to extract and encode hidden relationships between words and concepts within the text. LSI, for example, uses singular value decomposition to identify patterns and relationships within the text and represent them in a lower-dimensional space, while LDA uses probabilistic models to identify hidden topics within the text and represent them as a set of weighted terms. These techniques help the model understand the underlying meaning and context of the text, rather than just the individual words.
Overall, vector space models take into account the context and semantics of search queries and documents through a variety of techniques, including weighting, stemming, stop words, synonyms, and latent semantic analysis. By considering these factors, the model is able to more accurately understand and represent the meaning and context of the text, leading to more relevant and accurate search results.
How Do Vector Space Models Handle Synonyms And Variations In Language In Search Queries And Documents?
Vector space models are a mathematical representation of words or phrases in a given language. These models are used to analyze and understand the relationships between words and phrases in order to improve search engine results and document retrieval.
One of the key ways in which vector space models handle synonyms and variations in language is through the use of word vectors.
Word vectors are mathematical representations of words or phrases that are based on the context in which they are used. These vectors are created by analyzing large amounts of text data and determining the relationships between words or phrases. For example, if two words or phrases are frequently used together, they will likely have similar word vectors.
One of the main ways in which vector space models handle synonyms and variations in language is through the use of word embeddings. Word embeddings are a type of word vector that represents the meaning of a word or phrase in a continuous vector space. This allows the model to understand the relationships between different words or phrases and to identify synonyms or variations in language.
For example, if a search query contains the word "run," the model may use word embeddings to understand that this word is related to other words such as "jog," "sprint," or "race." This allows the model to return more relevant results for the search query, even if the query does not contain the exact words or phrases used in the documents.
In addition to word embeddings, vector space models also use techniques such as term frequency-inverse document frequency (TF-IDF) to handle synonyms and variations in language. TF-IDF is a measure of the importance of a word or phrase within a document or set of documents. Words or phrases that are more common in the overall collection of documents will have a lower TF-IDF score, while more unique or rare words or phrases will have a higher score.
By using TF-IDF, vector space models can identify the most important words or phrases in a given document or set of documents. This allows the model to understand the context and meaning of the words or phrases, even if they are synonyms or variations of other words or phrases.
Overall, vector space models handle synonyms and variations in language by using word vectors and techniques such as word embeddings and TF-IDF to understand the relationships between words and phrases. This allows the model to improve search engine results and document retrieval by returning more relevant results for a given query, even if the query does not contain the exact words or phrases used in the documents.
Can Vector Space Models Be Used To Optimize The Ranking Of Images And Other Multimedia In Search Results?
Vector space models, also known as vector spaces or linear algebra models, are mathematical tools used to represent and analyze text data. These models use vectors, or sets of numerical values, to represent each document or piece of text in a collection.
These vectors are then used to compare and analyze the relationships between different documents and identify patterns and trends.
One way that vector space models can be used to optimize the ranking of images and other multimedia in search results is through the use of image recognition algorithms. These algorithms analyze the visual content of an image and compare it to a database of images with known labels, such as "cat" or "beach." The algorithm then assigns a label to the image based on its visual content, which can be used to improve search results.
For example, if a user searches for "cat pictures," the search engine can use image recognition algorithms to identify images that contain cats and rank them higher in the search results. This helps to improve the accuracy and relevance of the search results, as it ensures that the user only sees images that are relevant to their query.
Vector space models can also be used to optimize the ranking of multimedia content, such as videos and audio files, by analyzing the audio or visual content of the media and assigning labels based on its content. For example, a video search engine could use vector space models to identify videos that contain a particular song or artist and rank them higher in the search results. This can be particularly useful for users who are looking for specific types of media, as it helps them find exactly what they are looking for more easily.
One of the main benefits of using vector space models for image and multimedia search is that they can be easily updated and improved over time. As new images and multimedia are added to the database, the algorithms can be updated to better recognize and classify them, resulting in more accurate and relevant search results. Additionally, vector space models can be trained on large datasets, which allows them to accurately classify a wide range of images and multimedia content.
There are, however, some limitations to using vector space models for image and multimedia search. One issue is that these models are not always able to accurately classify images or multimedia that contain complex or ambiguous content. For example, an image of a cat might be classified as a dog if it is partially obscured or if the cat is in an unusual pose. This can lead to inaccuracies in the search results, which can be frustrating for users.
Another limitation of vector space models is that they rely on the quality of the data used to train the algorithms. If the data is incomplete or inaccurate, the algorithms will not be able to accurately classify images and multimedia. This can be a problem if the data used to train the algorithms is not representative of the entire dataset, as it can lead to biases in the search results.
Despite these limitations, vector space models can still be very useful for optimizing the ranking of images and other multimedia in search results. By analyzing the visual and audio content of images and multimedia, these models can help search engines to provide more accurate and relevant results to users. As image recognition and multimedia classification algorithms continue to improve, vector space models will likely become an increasingly important tool for optimizing the ranking of images and other multimedia in search results.
How Do Vector Space Models Handle Misspellings And Typos In Search Queries?
Vector space models are a type of mathematical model used in information retrieval and natural language processing. They are used to represent the meaning of words and phrases in a mathematical way, allowing for the comparison and manipulation of these meanings.
One of the main challenges in using vector space models for search queries is how to handle misspellings and typos, which are common occurrences in search queries due to user error or lack of attention.
One way vector space models handle misspellings and typos is through the use of spelling correction algorithms. These algorithms identify misspellings and typos in a search query and suggest the correct spelling or typo. This helps improve the accuracy of the search results, as the correct spelling or typo will likely lead to more relevant results.
Another way vector space models handle misspellings and typos is through the use of fuzzy matching algorithms. These algorithms allow for the identification of similar words or phrases, even if there are differences in spelling or wording. This can be helpful in cases where the user has misspelled a word or made a typo, as the search results will still include relevant results based on the meaning of the misspelled or typoed word.
In addition to spelling correction and fuzzy matching algorithms, vector space models can also use synonym expansion to handle misspellings and typos. This involves replacing a misspelled or typoed word with a synonym or related word, which can help improve the accuracy of the search results. For example, if a user searches for "kitten," but misspells it as "kiten," the vector space model could use synonym expansion to replace "kiten" with "kitten," leading to more relevant search results.
Another approach used by vector space models to handle misspellings and typos is the use of language models. These models use statistical techniques to predict the likelihood of a given word or phrase being used in a given context, based on the words and phrases that typically appear before and after it. This can be helpful in cases where the user has made a typo or misspelling, as the language model can predict the correct word or phrase based on the context of the search query.
Overall, vector space models use a combination of spelling correction, fuzzy matching, synonym expansion, and language modeling to handle misspellings and typos in search queries. These techniques allow for the identification and correction of misspellings and typos, leading to more accurate and relevant search results for the user. However, it is important to note that these techniques are not perfect and may not always be able to accurately handle misspellings and typos, particularly if the user has made multiple errors or has used unconventional wording. In these cases, the search results may not be as relevant as they would be with a correctly spelled and typed query.
How Do Vector Space Models Handle Changes In Language And Terminology Over Time?
Vector space models are a type of mathematical representation used in natural language processing and information retrieval systems. They allow words and documents to be represented as vectors in a multi-dimensional space, where each dimension corresponds to a particular term or concept.
These models are widely used in various applications, including text classification, topic modeling, and information retrieval.
One of the key advantages of vector space models is their ability to handle changes in language and terminology over time. This is because they do not rely on explicit definitions or rules for word meanings, but rather on the relationships between words and their usage patterns in a given corpus of text.
As a result, they are able to adapt to new words and changes in language usage, as long as the underlying relationships between words are preserved.
For example, consider a vector space model that has been trained on a large corpus of text from the 1990s. If this model is used to process a document from the present day, it may encounter a number of new words or phrases that did not exist in the training corpus. However, the model can still make sense of these words by considering the context in which they appear and the relationships between them and other words in the document.
One way that vector space models handle changes in language and terminology over time is through the use of word embeddings. Word embeddings are low-dimensional vector representations of words that capture the relationships between words in a given corpus. They are created by training a neural network on a large dataset of text, and the resulting word embeddings capture the patterns of co-occurrence between words in the dataset.
Since word embeddings are learned from the data, they are able to capture the nuances and subtleties of language usage, as well as the changes in terminology over time. For example, if a new word or phrase becomes widely used in a particular field, it will likely have a unique word embedding that reflects its usage patterns and relationships with other words.
Another way that vector space models handle changes in language and terminology over time is through the use of dynamic embeddings. Dynamic embeddings are word embeddings that are updated over time to reflect changes in language usage. They can be trained on a dataset of text from a specific time period, and then updated with new data as it becomes available. This allows the model to adapt to changes in language and terminology over time, while still maintaining a consistent representation of the relationships between words.
In summary, vector space models are well-suited to handling changes in language and terminology over time due to their ability to capture the relationships between words and their usage patterns. Through the use of word embeddings and dynamic embeddings, these models can adapt to new words and changes in language usage, while still maintaining a consistent and accurate representation of the underlying relationships between words. This makes them a powerful tool for natural language processing and information retrieval systems, which often need to deal with constantly evolving language and terminology.
Can Vector Space Models Be Used To Optimize The Ranking Of Social Media Posts And Other User-generated Content?
Vector space models, also known as term vector models, are a mathematical representation of the relationship between a document and a set of terms, or words, within that document.
In the context of social media, vector space models can be used to optimize the ranking of posts and other user-generated content by analyzing the content and determining the relevance and importance of each term within the context of the social media platform.
One way vector space models can be used to optimize the ranking of social media posts is through the use of term frequency-inverse document frequency (TF-IDF) scores. TF-IDF scores are used to measure the importance of a term within a document relative to a corpus of documents. In the context of social media, the corpus of documents could be all of the posts on a particular platform, and the individual document being analyzed could be a single post. By calculating the TF-IDF scores for each term in a post, the vector space model can determine the importance of those terms within the context of the social media platform and use that information to rank the post.
Another way vector space models can be used to optimize the ranking of social media content is through the use of machine learning algorithms. These algorithms can be trained on a large dataset of social media posts and their associated engagement metrics (such as likes, comments, and shares) to learn patterns and correlations between the content of a post and its engagement. By analyzing the content of a new post and comparing it to the patterns learned by the machine learning algorithm, the vector space model can predict the likely engagement of the post and use that information to rank it.
One potential limitation of using vector space models to optimize the ranking of social media content is that they may not always accurately reflect the preferences and interests of the users on the platform. Vector space models rely on the presence and frequency of certain terms within a document to determine its relevance and importance, but this may not always accurately capture the factors that drive user engagement. For example, a post with a high number of relevant terms may not necessarily be more engaging than a post with fewer relevant terms but more visual or emotional appeal.
Another limitation of using vector space models to optimize the ranking of social media content is that they may not account for changes in user behavior or trends on the platform. Vector space models rely on static datasets and may not be able to adapt to changes in user preferences or trends in real-time. As a result, they may not always accurately reflect the most relevant or engaging content for users at any given moment.
Despite these limitations, vector space models can still be a useful tool for optimizing the ranking of social media content. By analyzing the content of posts and determining the relevance and importance of each term, vector space models can provide valuable insights into the factors that drive user engagement and can be used to rank content accordingly.
Additionally, by incorporating machine learning algorithms, vector space models can continuously learn and adapt to changes in user behavior and trends on the platform, improving their accuracy over time.
How Do Vector Space Models Compare To Other Techniques For Optimizing Search Results, Such As Machine Learning And Artificial Intelligence?
Vector space models and machine learning algorithms are both techniques that can be used to optimize search results.
However, there are some key differences between the two approaches that set them apart.
One of the main differences between vector space models and machine learning algorithms is the way that they process and analyze data. Vector space models are based on a mathematical representation of the relationships between different data points. These models create a vector for each data point, and then use these vectors to represent the relationships between the data points. This allows vector space models to accurately identify patterns and relationships within large datasets.
On the other hand, machine learning algorithms are designed to learn from data. These algorithms are able to analyze large datasets and identify patterns and relationships within the data. They are then able to use this information to make predictions or decisions. Machine learning algorithms are typically more complex and require more processing power than vector space models.
Another key difference between vector space models and machine learning algorithms is the way that they are used to optimize search results. Vector space models are commonly used to improve the relevance of search results by ranking documents based on their relevance to the search query. This is done by comparing the vectors of the search query and the documents in the search index. The more similar the vectors, the higher the ranking of the document.
Machine learning algorithms, on the other hand, are often used to improve the accuracy of search results by predicting the user's intent. These algorithms can analyze user behavior and use this information to determine what the user is likely to be searching for. This allows the search engine to return more accurate and relevant results for the user.
There are also some differences in the way that vector space models and machine learning algorithms are implemented. Vector space models are typically implemented using software algorithms, which are programmed to perform specific tasks. Machine learning algorithms, on the other hand, are often implemented using neural networks, which are complex systems of algorithms that are designed to mimic the way that the human brain works.
Finally, vector space models and machine learning algorithms differ in terms of their scalability and flexibility. Vector space models are generally more scalable than machine learning algorithms, as they are able to handle large datasets more efficiently. However, machine learning algorithms are generally more flexible than vector space models, as they are able to adapt and learn from new data over time.
In conclusion, vector space models and machine learning algorithms are both useful techniques for optimizing search results. Vector space models are typically more efficient and scalable, while machine learning algorithms are more flexible and able to adapt to new data. Both approaches have their strengths and limitations, and the best approach will depend on the specific needs of the application.
How Market Brew Uses Vector Space Models
Vector space models are a mathematical way of representing and analyzing the relationships between words or phrases in a given text. They are used in various applications, including information retrieval, natural language processing, and machine learning. Market Brew's AI SEO software utilizes vector space models in its search engine models in order to provide users with more relevant and accurate search results.
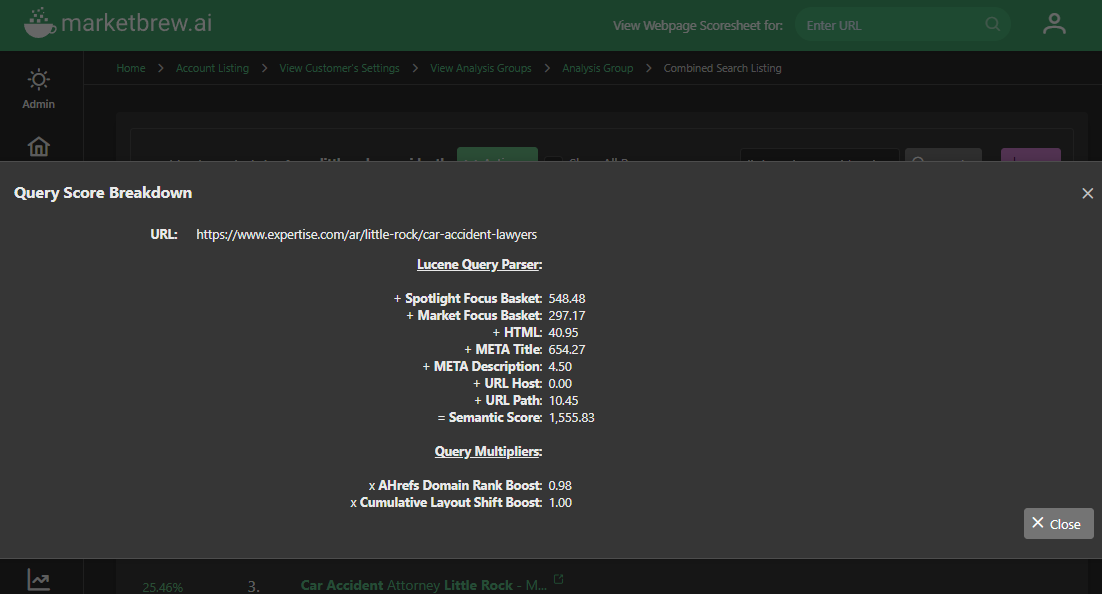
One way that Market Brew uses vector space models is through its Lucene Query Parser. This is a tool that helps to process and analyze search queries by breaking them down into individual words or phrases and assigning them a numerical value based on their relevance and importance. The Lucene Query Parser uses vector space models to compare the query terms to the terms in the documents being searched and to calculate the similarity between them. The more similar the terms are, the higher the score and the more relevant the document is considered to be.
Another way that Market Brew uses vector space models is through its Heading Vectors algorithm. This algorithm is designed to analyze the headings and subheadings of a document and assign them a numerical value based on their relevance to the search query. By doing this, the algorithm is able to identify the most important and relevant parts of a document and prioritize them in the search results. This helps to ensure that users are presented with the most relevant information at the top of the search results, rather than having to scroll through pages of less relevant content.
In addition to these algorithms, Market Brew also utilizes vector space models in its natural language processing (NLP) based algorithms. NLP is a field of computer science that focuses on the interactions between computers and human languages. These algorithms are used to analyze and understand the meaning and context of written or spoken language in order to perform tasks such as translation, summarization, and sentiment analysis.
By using vector space models, these algorithms are able to analyze the relationships between words and phrases in a given text and understand the overall meaning and context of the text. This helps to provide users with more accurate and relevant search results, as the algorithms are able to understand the intent behind a search query and provide results that are more closely related to what the user is looking for.

Overall, Market Brew's use of vector space models helps to improve the accuracy and relevance of its search engine by allowing it to analyze and understand the relationships between words and phrases in a given text.
By using these models, Market Brew is able to provide users with more accurate and relevant search results, which helps to improve the overall user experience and make the SEO software more effective and efficient.
Ready to Take Control of Your SEO?
See how Market Brew's predictive SEO models and expert team can unlock new opportunities for your site. Get tailored insights on how we can help your business rise above the competition.
Schedule a demonstration today via our Menu Button and Contact Form to discover how we engineer SEO success.
You May Also Like:
Guides & Videos
Knowledge Graph Semantic Algorithm Arc
History
Google Expertise Algorithm
Guides & Videos
Client-Side Rendering SEO Guide
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.