

Exploring The Potential Of SPARQL For SEO
This article explores the potential of SPARQL for SEO purposes.
We cover a range of topics including the basics of SPARQL, its relationship to SEO, and specific ways in which it can be used to optimize the structure and organization of a website, identify and fix technical SEO issues, extract and analyze data from structured data markup, perform keyword research and competitive analysis, monitor and track website performance, create and maintain a sitemap, generate and analyze log files, identify and fix broken links, and address duplicate content issues.
SPARQL (SPARQL Protocol and RDF Query Language) is a query language for retrieving and manipulating data stored in the Resource Description Framework (RDF) format, which is a standard for representing and exchanging data on the web.
While SPARQL is primarily used for querying and managing RDF data, it also has the potential to be a valuable tool for search engine optimization (SEO). In this article, we will examine the various ways in which SPARQL can be used to improve the visibility and ranking of a website in search results.
We will cover a range of topics including the basics of SPARQL, its relationship to SEO, and specific ways in which it can be used to optimize the structure and organization of a website, identify and fix technical SEO issues, extract and analyze data from structured data markup, perform keyword research and competitive analysis, monitor and track website performance, create and maintain a sitemap, generate and analyze log files, identify and fix broken links, and address duplicate content issues.
What is SPARQL and How Does it Relate to SEO?
SPARQL (SPARQL Protocol and RDF Query Language) is a query language designed specifically for querying data stored in the Resource Description Framework (RDF) format. RDF is a standard for representing and organizing data in a machine-readable way and it is often used for storing data about entities and their relationships in the form of a graph. This makes it ideal for representing complex data relationships, such as those found in large databases or on the web.
In terms of SEO (Search Engine Optimization), SPARQL can be useful for extracting data about a website or a particular page from search engines or other data sources. This can be useful for identifying issues or opportunities for improvement in a website's search ranking, as well as for tracking the performance of a website over time. For example, if a website owner wants to know how their website is ranking for a particular keyword, they could use SPARQL to query a search engine's data and retrieve the relevant information.
One way that SPARQL can be used for SEO is through the use of structured data. Structured data is information that is added to a website's HTML code in a standardized format, making it easier for search engines to understand and interpret the content on a webpage. By using structured data, a website can provide search engines with more context and meaning about the content on their site, which can help improve the site's search ranking.
SPARQL can also be used to extract data from external sources, such as social media platforms or online reviews, and use it to inform SEO strategies. For example, a website owner could use SPARQL to extract data about the number of social media shares or likes a page has received, and use this information to identify which pages on their site are most popular and worthy of further promotion.
In addition to its use in SEO, SPARQL is also commonly used in data analytics and data science, as it allows for the creation of complex queries that can extract insights from large datasets. It is a powerful tool for extracting and analyzing data from a variety of sources, and it can be useful for businesses or organizations looking to gain a better understanding of their data and make informed decisions based on that data.
Overall, SPARQL is a useful tool for extracting and analyzing data from a variety of sources, including search engines and other data sources on the web. It can be particularly useful for SEO, as it allows website owners to extract data about their site's performance and identify opportunities for improvement in their search ranking.
How Can SPARQL Be Used To Optimize The Structure And Organization Of A Website For Search Engines?
SPARQL (SPARQL Protocol and RDF Query Language) is a powerful query language used to retrieve and manipulate data stored in the Resource Description Framework (RDF) format.
RDF is a standard for representing data on the web in a machine-readable and interoperable way, and it is often used for representing data related to the structure and organization of a website.
Using SPARQL, website developers and administrators can query the RDF data stored on their website to gain insights into the structure and organization of their site, and use this information to optimize their site for search engines.
Here are a few ways in which SPARQL can be used to optimize the structure and organization of a website for search engines:
- Identify and fix broken links: SPARQL can be used to identify and fix broken links on a website. Broken links can negatively impact the user experience and the search engine ranking of a website. By using SPARQL to query the RDF data on the website, developers can identify any broken links and fix them to improve the overall structure and organization of the site.
- Improve the navigation structure: SPARQL can be used to analyze the navigation structure of a website and identify any areas that may be confusing or difficult for users to navigate. This can help website administrators improve the overall usability of the site and make it more search engine friendly.
- Optimize the content hierarchy: SPARQL can be used to analyze the hierarchy of content on a website and identify any areas that may be difficult for search engines to crawl and index. By optimizing the content hierarchy, website administrators can ensure that search engines are able to easily understand and index the content on their site, which can lead to higher search engine rankings.
- Analyze the inbound and outbound links: SPARQL can be used to analyze the inbound and outbound links on a website and identify any links that may be broken or irrelevant. By improving the quality and relevance of inbound and outbound links, website administrators can improve the overall structure and organization of their site and make it more search engine friendly.
- Identify and fix duplicate content: SPARQL can be used to identify and fix any duplicate content on a website. Duplicate content can negatively impact a website's search engine ranking and can be confusing for users. By using SPARQL to identify and fix duplicate content, website administrators can improve the overall structure and organization of their site.
Overall, SPARQL can be a valuable tool for website developers and administrators looking to optimize the structure and organization of their site for search engines. By using SPARQL to query the RDF data on their website, they can gain insights into the structure and organization of their site and identify any areas that may need improvement.
By fixing broken links, improving the navigation structure, optimizing the content hierarchy, analyzing inbound and outbound links, and identifying and fixing duplicate content, website administrators can make their site more search engine friendly and improve their search engine rankings.
Can SPARQL Be Used To Identify And Fix Technical SEO Issues On A Website?
SPARQL, or SPARQL Protocol and RDF Query Language, is a language designed for querying and manipulating data stored in the Resource Description Framework (RDF) format.
It is commonly used in the field of semantic web technologies, which aim to make data more accessible and understandable by machines.
One of the primary applications of SPARQL is in the identification and resolution of technical SEO issues on websites. Technical SEO refers to the various technical factors that can impact a website's search engine rankings, including things like site speed, mobile-friendliness, and crawlability. By using SPARQL to query and analyze data about a website, it is possible to identify and fix many common technical SEO issues.
For example, if a website has poor site speed, this can be identified by querying data about page load times and other performance metrics. Using SPARQL, it is possible to extract data about these metrics and analyze it to identify areas where the site is performing poorly. This information can then be used to optimize the site's code, images, and other assets to improve its speed.
Similarly, if a website is not mobile-friendly, this can be identified by querying data about the site's layout and design. By analyzing this data, it is possible to determine whether the site is responsive or whether it has separate mobile and desktop versions. This information can be used to make changes to the site's design and layout to improve its mobile-friendliness.
Crawlability is another important aspect of technical SEO that can be improved using SPARQL. Crawlability refers to the ease with which search engine bots can discover and index pages on a website. By querying data about the site's URLs, links, and other components, it is possible to identify areas where the site is difficult for search engines to crawl. This information can be used to make changes to the site's structure and navigation to improve its crawlability.
In addition to these technical SEO issues, SPARQL can also be used to identify and fix other types of problems on a website. For example, it can be used to identify and fix broken links, duplicate content, and other issues that can negatively impact a site's search engine rankings.
Overall, SPARQL is a powerful tool that can be used to identify and fix many technical SEO issues on a website. By querying and analyzing data about the site, it is possible to identify areas where the site is performing poorly and make changes to improve its search engine rankings. This can help to drive more traffic to the site and increase its overall visibility on the web.
How Can SPARQL Be Used To Extract And Analyze Data From Structured Data Markup Such As Schema.org?
SPARQL (SPARQL Protocol and RDF Query Language) is a query language designed specifically for extracting and analyzing data from structured data markup, such as schema.org.
It is based on the Resource Description Framework (RDF), which is a standard for representing and storing data in a web-based format.
One of the main benefits of using SPARQL to extract and analyze data from schema.org is that it allows users to perform complex queries on the data in order to gain insights and understand trends.
For example, if a user wanted to know how many websites are using a particular schema.org markup, they could use SPARQL to query the data and retrieve the number of websites that are using that markup.
To use SPARQL to extract and analyze data from schema.org, users must first understand the structure of the data and the relationships between different pieces of information. The schema.org vocabulary includes a wide range of categories and types of data, such as information about products, events, people, and places. To extract and analyze data from schema.org, users must understand how these categories and types of data are related to one another.
Once users have a good understanding of the structure of the data and the relationships between different pieces of information, they can begin to write SPARQL queries to extract and analyze the data. SPARQL queries typically consist of three main parts: a SELECT clause, a WHERE clause, and an ORDER BY clause.
The SELECT clause specifies the variables that the query should return. For example, if a user wanted to extract data about the number of websites using a particular schema.org markup, they could use a SELECT clause like this:
SELECT ?website
The WHERE clause specifies the conditions that the data must meet in order to be included in the query results. For example, if a user wanted to extract data about the number of websites using a particular schema.org markup, they could use a WHERE clause like this:
WHERE {
?website schema:type "Product" .
}
The ORDER BY clause specifies the order in which the query results should be returned. For example, if a user wanted to extract data about the number of websites using a particular schema.org markup and then sort the results by the number of websites using that markup, they could use an ORDER BY clause like this:
ORDER BY ?website
Once users have written their SPARQL queries, they can execute them using a SPARQL endpoint or a SPARQL client. A SPARQL endpoint is a web-based service that allows users to execute SPARQL queries and retrieve the results. A SPARQL client is a software tool that allows users to execute SPARQL queries and retrieve the results.
There are many different ways that users can use SPARQL to extract and analyze data from schema.org.
Some common use cases include extracting data about the:
- number of websites using a particular schema.org markup
- types of products being sold on different websites
- location and dates of events being advertised on different websites
- personal information of individuals being advertised on different websites
- locations of places being advertised on different websites
Overall, SPARQL is a powerful tool for extracting and analyzing data from structured data markup such as schema.org. It allows users to perform complex queries on the data in order to gain insights and understand trends. By understanding the structure of the data and the relationships between different pieces of information, users can use SPARQL to extract and analyze data from schema.org in a variety of different ways, depending on their needs and goals.
In addition to extracting and analyzing data, SPARQL can also be used to update and modify data stored in schema.org. This can be useful for adding new data or correcting errors in existing data. For example, if a user wanted to add information about a new product to schema.org, they could use SPARQL to insert the new data into the schema.org database.
SPARQL is a widely used and well-supported query language, with many resources and tools available to help users get started. For example, there are numerous online tutorials and guides that can help users learn how to write and execute SPARQL queries, as well as SPARQL clients and other tools that can make it easier to work with SPARQL and schema.org data.
In conclusion, SPARQL is a powerful tool for extracting and analyzing data from structured data markup such as schema.org. By understanding the structure of the data and the relationships between different pieces of information, users can use SPARQL to gain insights and understand trends, and to update and modify data stored in schema.org. With the wide range of resources and tools available to support the use of SPARQL, it is a valuable tool for anyone looking to extract and analyze data from schema.org or other structured data markup.
Can SPARQL Be Used To Perform Keyword Research And Competitive Analysis For SEO?
SPARQL, or the SPARQL Protocol and RDF Query Language, is a powerful tool for querying and manipulating data stored in the Resource Description Framework (RDF) format.
It is commonly used in the field of Semantic Web and Linked Data, as it allows users to easily retrieve and analyze large datasets from a variety of sources.
While SPARQL is primarily used for querying data, it can also be used for keyword research and competitive analysis for SEO purposes.
One way to use SPARQL for keyword research is to query data from search engines and other online sources to identify the most popular and relevant keywords for a particular topic or industry. For example, a marketing agency could use SPARQL to query Google's search data and retrieve the most searched terms related to a specific product or service. This information could be used to optimize website content, titles, and meta tags to increase the chances of ranking higher in search results.
In addition to keyword research, SPARQL can also be used to perform competitive analysis for SEO purposes. By querying data from a competitor's website or social media profiles, it is possible to identify the keywords and phrases that they are using to attract traffic and generate leads. This information can be used to inform the content and keyword strategy for one's own website, allowing them to better compete with their rivals.
One way to perform competitive analysis with SPARQL is to query data from a competitor's website and extract the keywords used in their titles, meta tags, and other on-page elements.
This information can be compared to the keywords used on one's own website to identify any gaps or areas of overlap. By identifying which keywords the competitor is using, one can optimize their own content to rank higher for those terms and potentially outrank their competitor in search results.
In addition to on-page elements, SPARQL can also be used to analyze a competitor's backlink profile. By querying data from a link analysis tool such as Majestic or Ahrefs, it is possible to identify the websites and pages that are linking to the competitor's website. This information can be used to identify opportunities for building backlinks of one's own and improving their own website's authority and ranking potential.
While SPARQL is a powerful tool for keyword research and competitive analysis, it is important to note that it requires a certain level of technical expertise to use effectively. It is not a tool that is accessible to everyone, and it may require some training and practice to become proficient in using it. Additionally, SPARQL may not always be the most efficient or cost-effective solution for SEO purposes, as it requires a significant time investment to set up and maintain queries.
In summary, SPARQL can be used for keyword research and competitive analysis for SEO purposes by querying data from search engines, websites, and other online sources to identify popular and relevant keywords, as well as analyzing a competitor's on-page elements and backlink profile. However, it requires a certain level of technical expertise and may not always be the most efficient or cost-effective solution.
How Can SPARQL Be Used To Monitor And Track The Performance Of A Website In Search Results?
SPARQL (SPARQL Protocol and RDF Query Language) is a powerful query language that can be used to retrieve and manipulate data stored in the Resource Description Framework (RDF) format.
It is widely used in the field of semantic web and linked data, and has become a popular choice for data management and analysis in various domains, including web search.
One way in which SPARQL can be used to monitor and track the performance of a website in search results is by querying data from web search engines or search result APIs that provide structured data in RDF format. For example, Google provides a search result API that allows developers to retrieve search results in RDF/XML or JSON-LD format, which can be easily parsed and queried using SPARQL.
With SPARQL, it is possible to extract various metrics and indicators related to the performance of a website in search results, such as the ranking of the website for specific keywords or queries, the number of clicks and impressions received by the website, and the average click-through rate (CTR) and conversion rate of the website. These metrics can be used to measure the effectiveness of the website's search engine optimization (SEO) efforts and to identify opportunities for improvement.
To monitor and track the performance of a website in search results, one could use SPARQL to query data from the search result API on a regular basis, for example daily or weekly. The results of the query could then be stored in a database or a data warehouse, and analyzed using visualization tools such as Tableau or Google Charts.
Using SPARQL, it is possible to analyze the performance of a website in search results over time, and to compare the performance of the website to that of its competitors. For example, one could use SPARQL to compare the ranking of a website for a particular keyword or query with that of its competitors, or to compare the CTR of the website with that of its competitors. This can help identify trends and patterns in the performance of the website, and can inform decisions about how to optimize the website for search engines.
In addition to querying data from search result APIs, SPARQL can also be used to query data from other sources, such as social media platforms or web analytics tools, in order to get a more comprehensive view of the performance of a website in search results. For example, one could use SPARQL to query data from social media platforms such as Twitter or Facebook to identify trends in the number of shares or likes of the website's content, and to compare these trends with the performance of the website in search results.
Another way in which SPARQL can be used to monitor and track the performance of a website in search results is by using it to query data from web crawlers or web scraping tools that extract structured data from websites. This can help identify changes in the content or structure of the website that may affect its performance in search results. For example, one could use SPARQL to query data from a web crawler that extracts data about the titles, meta descriptions, and headings of the website's pages, and to compare these data with the ranking of the website in search results.
In conclusion, SPARQL is a powerful tool that can be used to monitor and track the performance of a website in search results by querying data from search result APIs, social media platforms, web analytics tools, and web crawlers. By analyzing these data using SPARQL and visualization tools, it is possible to identify trends and patterns in the performance of the website, and to make informed decisions about how to optimize the website for search engines.
Can SPARQL Be Used To Create And Maintain A Sitemap For A Website?
SPARQL, or the SPARQL Protocol and RDF Query Language, is a standard query language for retrieving and manipulating data stored in the Resource Description Framework (RDF) format.
It is used to query and manipulate data stored in triplestores, or databases that store RDF data, and is commonly used in the Semantic Web and Linked Data communities.
One potential use for SPARQL is in the creation and maintenance of a sitemap for a website.
A sitemap is a hierarchical representation of the pages and content on a website, and is used to help search engines and other web crawlers understand and index the structure and organization of a website. A sitemap can be created and maintained in a number of different ways, including manually creating and updating a list of pages, using a sitemap generator tool, or using a sitemap management system.
Using SPARQL to create and maintain a sitemap for a website has several potential advantages. One advantage is that SPARQL can be used to query and extract data from a variety of different sources, including databases, websites, and other online resources. This means that a SPARQL-based sitemap can include not only pages and content from the main website, but also data from other sources that are relevant or related to the website.
Another advantage of using SPARQL to create and maintain a sitemap is that it allows for the use of RDF data to represent the structure and organization of the website. RDF data is a flexible and extensible data model that can be used to represent a wide range of different types of information, including web pages, content, and relationships between different pieces of data.
This means that a SPARQL-based sitemap can include not only the page titles and URLs of a website, but also additional metadata and information about the pages and content, such as their subject matter, language, and other relevant details.
Using SPARQL to create and maintain a sitemap also has the potential to make the sitemap more dynamic and updatable. SPARQL queries can be set up to continuously monitor and track changes to the data sources that are being queried, and can automatically update the sitemap when changes are detected. This can help to ensure that the sitemap is always up to date and accurately reflects the current structure and content of the website.
However, there are also some potential challenges and limitations to using SPARQL to create and maintain a sitemap for a website. One challenge is that SPARQL is a complex and technical language that may require specialized knowledge and expertise to use effectively. This may make it more difficult for non-technical users to create and maintain a SPARQL-based sitemap, and may require the use of specialized tools or software to manage the sitemap.
Another challenge is that SPARQL relies on the use of RDF data, which may not be available or easy to obtain for all websites or types of content. In order to use SPARQL to create and maintain a sitemap, it may be necessary to either create or convert existing data into RDF format, which can be a time-consuming and resource-intensive process.
Finally, using SPARQL to create and maintain a sitemap may also require the use of a triplestore or other database to store and manage the sitemap data. This can add an additional layer of complexity and overhead to the process, and may require additional resources and infrastructure to support the sitemap.
In conclusion, while it is possible to use SPARQL to create and maintain a sitemap for a website, there are also several challenges and limitations to consider. SPARQL's ability to query and extract data from a variety of sources and represent it in the flexible and extensible RDF data model make it a powerful tool for creating dynamic and updatable sitemaps. However, the technical complexity of SPARQL and the need for specialized tools and infrastructure may make it more difficult for non-technical users to implement and maintain a SPARQL-based sitemap.
Additionally, the availability and use of RDF data may also be a limiting factor in using SPARQL for sitemap creation and maintenance. Overall, the decision to use SPARQL for sitemap creation and maintenance will depend on the specific needs and resources of the website and the individuals or organizations responsible for managing it.
How Can SPARQL Be Used To Generate And Analyze Log Files For SEO Purposes?
SPARQL, or SPARQL Protocol and RDF Query Language, is a query language specifically designed for retrieving and manipulating data stored in the Resource Description Framework (RDF) format.
It is used in the field of semantic web technologies and allows users to query and manipulate large datasets in a more efficient and flexible manner.
One way that SPARQL can be used for SEO purposes is by generating and analyzing log files.
Log files are records of activity that occur on a website, including visitor behavior and site performance. By analyzing these log files, SEO professionals can gain insights into how well a website is performing and where there may be areas for improvement.
To generate log files using SPARQL, a user would first need to set up an RDF dataset containing the relevant data. This dataset could include information about website visitors, such as their location, device, and pages visited. It could also include data about the website itself, such as page views, bounce rates, and loading times.
Once the dataset is set up, the user can use SPARQL to create queries that extract and filter the data in a specific way. For example, a user might create a query to identify the top-performing pages on the website based on page views or to see which countries have the highest bounce rates.
Once the log files have been generated, the user can then use SPARQL to analyze the data and draw insights from it. For example, the user could use SPARQL to identify trends in visitor behavior or to identify any issues with the website's performance. This analysis can be used to inform SEO strategy and identify areas for improvement.
One potential use of SPARQL in SEO is to analyze the impact of specific SEO tactics. For example, if a website has recently implemented a new keyword strategy or made changes to its website structure, a user could use SPARQL to analyze log files and see how these changes have affected the website's performance. This could help the user determine whether the changes were effective and identify areas for further optimization.
In addition to generating and analyzing log files, SPARQL can also be used to extract and analyze data from other sources, such as social media platforms or search engine results pages. This can provide a more comprehensive view of a website's performance and help SEO professionals identify new opportunities for growth.
Overall, SPARQL is a powerful tool for generating and analyzing log files for SEO purposes. It allows users to extract and filter data in a flexible and efficient manner, and to draw insights from large datasets that can inform SEO strategy and improve website performance. By using SPARQL, SEO professionals can gain a deeper understanding of how their website is performing and identify areas for optimization, ultimately helping to drive traffic and improve search engine rankings.
Can SPARQL Be Used To Identify And Fix Broken Links On A Website?
SPARQL, or SPARQL Protocol and RDF Query Language, is a query language used to query and manipulate data stored in the Resource Description Framework (RDF) format. It is often used in the field of semantic web technology, where data is structured in a way that can be easily understood by computers.
One potential use for SPARQL is in identifying and fixing broken links on a website.
Broken links, or dead links, are hyperlinks that lead to a webpage that no longer exists or is not available. These links can be frustrating for users, as they may lead to error messages or blank pages. They can also negatively impact search engine rankings, as search engines may consider a website with broken links to be less valuable and relevant.
To use SPARQL to identify broken links on a website, a query would need to be written that searches for all links on the website and checks their status. This could be done by querying the RDF data that describes the website's content and structure, including the URLs of all pages and links.
Once the query has identified all of the links on the website, it can then check their status by sending a request to each URL and evaluating the response. If the response is an error message or a page that is not found, the link can be considered broken and added to a list of links to be fixed.
To fix the broken links, the website's content management system (CMS) or the website's code can be updated to remove or replace the broken links. This can be done manually or automated using a script or program that processes the list of broken links and updates the website accordingly.
There are several benefits to using SPARQL to identify and fix broken links on a website. One benefit is that it can be done quickly and efficiently. By using a query language, the process of identifying and fixing broken links can be automated, saving time and effort compared to manually checking each link.
Another benefit is that SPARQL can be used to identify broken links on websites that use RDF data. This is particularly useful for websites that use RDF to store and describe their content, as it allows for a more comprehensive search for broken links.
In addition, SPARQL can be used to identify broken links on multiple websites at once. This can be useful for websites that link to external resources or for businesses that manage multiple websites. By querying all of the websites at once, broken links can be identified and fixed more efficiently.
There are also some limitations to using SPARQL to identify and fix broken links on a website. One limitation is that it is only effective on websites that use RDF data. If a website does not use RDF, SPARQL will not be able to query the website's content and structure.
Another limitation is that SPARQL cannot identify broken links on websites that are not accessible to the query. For example, if a website is password protected or behind a paywall, SPARQL will not be able to access the website's data and identify any broken links.
In conclusion, SPARQL can be used to identify and fix broken links on a website by querying the website's RDF data and checking the status of each link. This can be done quickly and efficiently, and can be used on multiple websites at once. However, it is only effective on websites that use RDF data and are accessible to the query.
How Can SPARQL Be Used To Identify And Fix Duplicate Content Issues On A Website?
Duplicate content is a common issue that can occur on websites, and it can negatively impact the user experience and search engine rankings.
Duplicate content refers to identical or nearly identical content that appears on multiple pages or websites. This can occur due to a variety of reasons, such as content being copied and pasted from other sources, or multiple pages on the same website having the same content.
One way to identify and fix duplicate content issues on a website is through the use of SPARQL (SPARQL Protocol and RDF Query Language).
SPARQL is a query language specifically designed for querying and manipulating data stored in the Resource Description Framework (RDF) format. RDF is a standard for representing data in the form of subject-predicate-object triples, and it is often used for storing and representing data on the web.
To identify duplicate content using SPARQL, we can use the SELECT query to retrieve all the triples that contain a specific piece of content. For example, if we want to find all the pages on a website that contain the phrase "duplicate content," we can use the following SPARQL query:
SELECT ?page
WHERE {
- ?page rdf:type schema:WebPage ;
- schema:text "duplicate content" .
}
This query will return a list of all the pages on the website that contain the phrase "duplicate content." We can then use this list to identify any pages that contain duplicate content and take appropriate action to fix the issue.
Once we have identified the pages with duplicate content, we can use SPARQL to fix the issue in a number of ways. One approach is to use the DELETE query to remove the duplicate content from the page. For example, if we want to delete all instances of the phrase "duplicate content" from a specific page, we can use the following SPARQL query:
DELETE {
- ?page schema:text "duplicate content" .
}
WHERE {
- ?page rdf:type schema:WebPage ;
- schema:text "duplicate content" .
}
This query will delete all instances of the phrase "duplicate content" from the specified page.
Another approach is to use the INSERT query to add unique content to the page. For example, if we want to insert the phrase "unique content" into a specific page, we can use the following SPARQL query:
INSERT {
?page schema:text "unique content" .
}
WHERE {
?page rdf:type schema:WebPage ;
schema:text "duplicate content" .
}
This query will insert the phrase "unique content" into the specified page, replacing any instances of "duplicate content."
In addition to these approaches, we can also use SPARQL to redirect users from duplicate content pages to the original page. For example, if we have identified two pages with duplicate content, we can use the following SPARQL query to redirect users from the duplicate page to the original page:
INSERT {
?duplicatePage schema:isPartOf ?originalPage .
}
WHERE {
?duplicatePage rdf:type schema:WebPage ;
schema:text "duplicate content" .
?originalPage rdf:type schema:WebPage ;
schema:text "unique content" .
}
This query will add a relationship between the duplicate page and the original page, indicating that the duplicate page is part of the original page. This can then be used to redirect users from the duplicate page to the original page, ensuring that users are not presented with duplicate content.
It is important to regularly check for and fix duplicate content issues on a website, as duplicate content can have negative impacts on user experience and search engine rankings. SPARQL can be an effective tool for identifying and fixing duplicate content issues, as it allows us to query and manipulate data stored in the RDF format. By using SPARQL to delete duplicate content, insert unique content, and redirect users to the original page, we can ensure that our website is free of duplicate content and provides a positive experience for users.
How Market Brew Uses SPARQL
Market Brew's advanced AI SEO software uses SPARQL, a powerful query language designed specifically for working with RDF data, to power many of the semantic algorithms in its suite of algorithms.
RDF, or Resource Description Framework, is a data model that represents information as a series of interconnected statements or triples. These triples consist of a subject, a predicate, and an object, and they are used to describe relationships between different entities in a way that is both flexible and highly expressive.
Market Brew's Knowledge Graph is built using RDF data, and it contains billions of triples that describe a wide range of topics and relationships. This data is stored in a large, distributed database, and it can be accessed and queried using SPARQL.
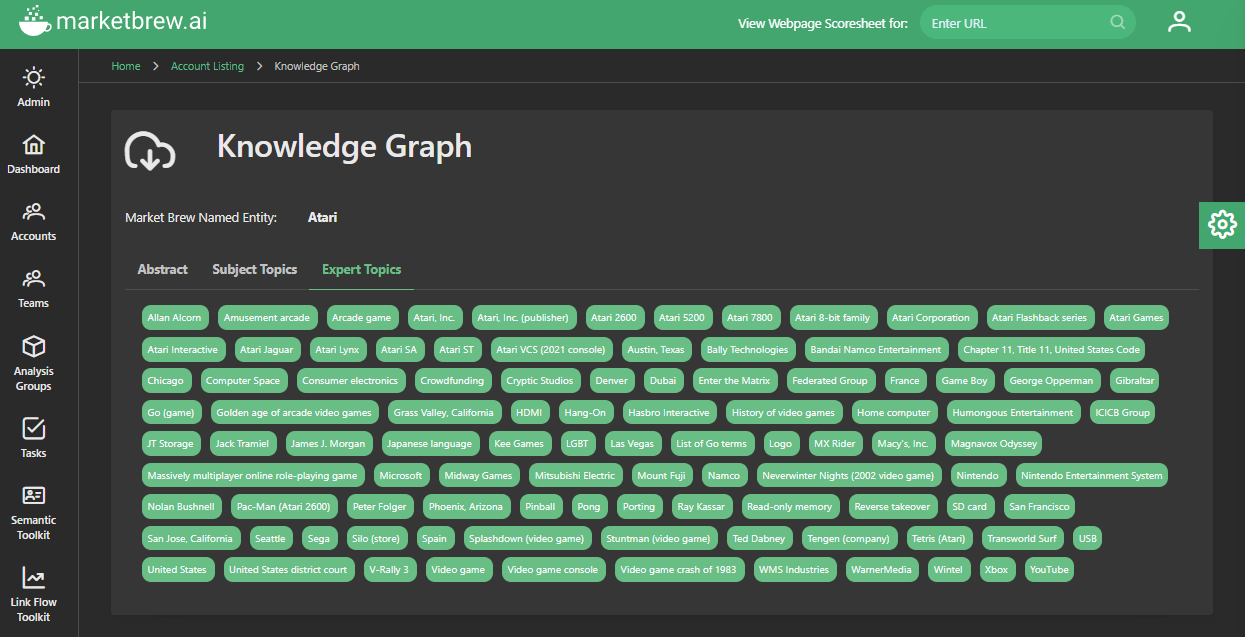
One of the primary ways that Market Brew uses SPARQL is to build related entities and topic clusters for any given web page. When a user searches for a particular term or phrase, Market Brew's search engine uses SPARQL to retrieve and traverse the data in the Knowledge Graph, looking for pages that are related to the search term in some way.
For example, if a user searches for "coffee," Market Brew's search engine might use SPARQL to find pages that are related to coffee in some way, such as pages about coffee beans, coffee brewing techniques, or coffee shops. It might also use SPARQL to find pages that are related to coffee in more indirect ways, such as pages about health benefits of coffee or coffee culture.
In addition to building related entities and topic clusters, Market Brew also uses SPARQL to power its Spotlight algorithm and Expertise algorithm. The Spotlight algorithm is designed to highlight the most relevant and important information on a given web page, and it uses SPARQL to identify and extract key data points from the Knowledge Graph.
The Expertise algorithm, on the other hand, is designed to help users find pages that are written by experts in a particular field. It uses SPARQL to identify pages that are written by individuals with expertise in a particular topic, and it ranks these pages higher in the search results.
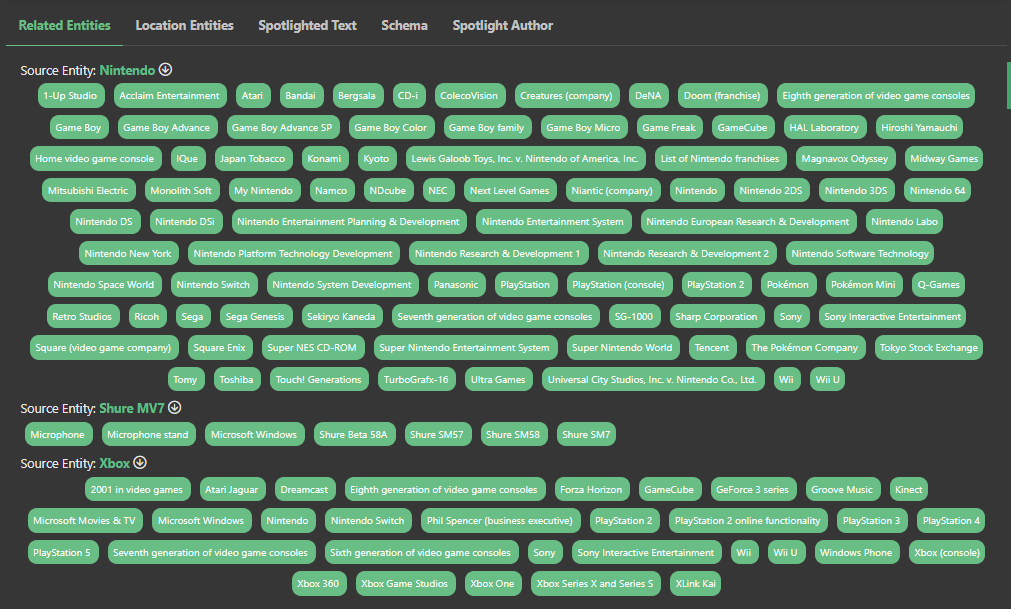
Overall, Market Brew's use of SPARQL is an integral part of its search engine technology, and it allows the company to deliver highly relevant and accurate search engine models to its users.
By leveraging the power of SPARQL and the RDF data model, Market Brew is able to create a rich and highly interconnected knowledge base that is able to provide its algorithms with the information they need, no matter what they are looking for. This, in turn, provides users a precise look at modern semantic algorithms that are now driving many of the search results.
Ready to Take Control of Your SEO?
See how Market Brew's predictive SEO models and expert team can unlock new opportunities for your site. Get tailored insights on how we can help your business rise above the competition.
Schedule a demonstration today via our Menu Button and Contact Form to discover how we engineer SEO success.
You may also like
Guides & Videos
Sentiment Analysis in SEO
Guides & Videos
SEO Internal Linking Detailed Guide
Guides & Videos
Others