
Semantic Breakthrough: An Exploration of Sentence-BERT and Its Influence on SEO
Sentence-BERT, developed to provide advancements in Natural Language Processing (NLP), significantly contributes to semantic textual similarity analysis and can enhance Search Engine Optimization (SEO) strategies.
This transformer-based model differs from classical BERT models by incorporating sentence-level word embeddings, thus providing quicker and more accurate results. Adoption of Sentence-BERT aids in generating SEO-friendly content, potentially helping in fixing SEO penalties while boosting content rankings.
However, its implementation might lead to a few challenges and is not exempt of limitations.
This article will delve into the purpose, features, benefits, and practical applications of Sentence-BERT, explore its potential issues, and discuss how it can shape the future of SEO strategies.
The birth of Sentence-BERT revolutionized the realms of Natural Language Processing (NLP) and Search Engine Optimization (SEO).
A step forward from traditional BERT models, it embeds entire sentence inputs, paving the way for transforming the analyses of semantically similar texts. It also assists in creating SEO-friendly content by understanding and analyzing the context deeply.
Despite some challenges - like resource-intensive computational requirements - Sentence-BERT’s high efficiency and accuracy are hard to dismiss.
This piece aims to unwrap all the facets of Sentence-BERT, dwelling on its purpose and unique aspects, its benefits in SEO, the potential difficulties one might face during its implementation, and how its existence could impact future SEO practices.
What is the Purpose of Sentence-BERT in Natural Language Processing?
Search Engine Optimization (SEO) lays significant emphasis on understanding user queries to provide the most relevant search results. This is where Natural Language Processing (NLP) systems like Sentence-BERT (SBERT) come into play. SBERT is a modification of the original BERT model, designed to yield better computational performance and more efficient handling of sentence representations.
Essentially, the purpose of Sentence-BERT is to generate semantically meaningful sentence embeddings. Original BERT model was not optimized to compute sentence embeddings. In order to obtain sentence embeddings, BERT uses a technique known as pooling on the output of tokens from the transformer model. Mean pooling and max pooling are the two prevalent strategies for this. However, such pooled embeddings often fail to capture the semantic meaning of sentences accurately.
To overcome these limitations, Sentence-BERT was proposed, which adapts the original BERT model by adding a siamese and triplet network structure. It uses techniques like cosine similarity to compare the closeness of two sentences. These modifications enable SBERT to perform faster and more accurately than the original BERT model when it comes to sentence embeddings. For instance, the scalability of SBERT allows quick searches among large collections of sentences in semantic search applications that SEO widely employs.
SBERT also plays a significant role in transforming the world of SEO by improving the efficiency of search queries and results. It handles conversational queries, a game-changer in SEO, as users often use voice-based searches in natural language. SBERT’s ability to compute sentence embeddings quickly and accurately allows it to understand the semantic meaning behind these queries. This leads to more relevant search results, which is a core feature of successful SEO.
Another prime focus of SBERT is improving semantic textual similarity, which determines how similar two sentences are in meaning. This plays a crucial role in ranking, machine translation and paraphrase detection, heavily used in SEO strategies. Normalizing search engine data using SBERT can lead to better recognition of similar search terms or phrases used in multiple documents, listings or websites. It enhances the process of document clustering, information retrieval and content-based recommendations, thereby improving the efficiency of search engines.
SBERT's wide-ranging applications in artificial intelligence are valuable aids in content analysis, automated customer support, chatbots, and more. Enhancing customer support chatbots with SBERT can lead to understanding customer queries better and providing more accurate solutions, improving overall user experience, an essential aspect in SEO.
How Does Sentence-BERT Differ from Traditional BERT Models?
Search Engine Optimization (SEO) evolves continuously, striving for more efficiency and accuracy in processing information. One of the lead players in this field is Google’s BERT (Bidirectional Encoder Representations from Transformers), a transformer-based machine learning technique for natural language processing (NLP) pre-training. BERT marked a significant evolution in NLP by enabling models to better understand the context of words in a given sentence. However, while sturdy, BERT isn't without its shortcomings. As we dive deeper into the realm of SEO, we encounter Sentence-BERT or SBERT, an improved version of the original BERT model.
The fundamental difference between SBERT and traditional BERT models lies primarily in how they handle and interpret sentences. BERT, being a word-level model, interprets one word at a time. To comprehend a sentence, traditional BERT examines every single word in the context of all the other words of the sentence. While this is excellent for understanding word nuances, it’s computationally expensive and time-consuming. On the other hand, SBERT operates at the sentence-level, embedding entire sentences into vectors which not only increases computational speed but also enhances models' semantic understanding.
SBERT further differs from BERT by incorporating Siamese and Triplet network structures into its architecture. These structures empower SBERT for semantic similarity tasks, a vital aspect of the SEO world. A Siamese network consists of two parallel networks joined by their outputs and the Triplet network takes three inputs instead of two. By processing sentence pairs simultaneously, these networks offer optimized solutions for tasks related to paraphrase identification, semantic textual similarity, or clustering algorithms.
Another major advancement with SBERT is its inherent support of supervision. Given pairs of semantically equivalent sentences, SBERT learns to minimize the distance between sentence embeddings of these pairs. This supervised training, when combined with the power of transformer networks, helps SBERT create semantically meaningful sentence embeddings in a single pass.
The contrast between BERT's masking-based training strategy, where words were predicted based on their context and SBERT's ability to derive semantically meaningful sentences directly, reflects in their performance. SBERT outperforms BERT in large-scale information retrieval tasks, delivering more refined results quicker.
Importantly for SEO, SBERT's capacity for understanding sentence semantics, rather than solely word semantics, allows for a more robust, nuanced understanding of content. This capacity can yield richer insights into search intent, potentially resulting in more targeted SERPs (Search Engine Result Pages) and better user experience.
Given that search engines’ core task is to understand and organize information, the evolution from BERT to Sentence-BERT illustrates a crucial development. SBERT effectively addresses some pressing issues in SEO, offering a more potent technology for search engine algorithms. It's faster, more accurate, and more semantic-sensitive than its predecessor, emphasizing its role in the future evolution of search engine optimization.
What Improvements Does Sentence-BERT Provide in Semantic Textual Similarity Analysis?
Semantic Textual Similarity (STS) analysis is a crucial part of natural language processing (NLP) tasks such as Search Engine Optimization (SEO). By understanding semantic similarities between various phrases or sentences, search engines can provide more accurate results, enhancing the user's overall experience. Initially, Google's BERT (Bidirectional Encoder Representations from Transformers) advanced the field in semantic understanding. Further, the development of Sentence-BERT (SBERT), a modification of BERT, introduced significant improvements in the STS analyses domain.
The primary enhancement that Sentence-BERT offers over traditional BERT is in terms of computational efficiency. BERT works efficiently when dealing with individual sentences. However, it becomes computationally expensive and time-consuming when it needs to compare multiple sentences for semantic similarity. This is because BERT requires comparisons between each possible pair of sentences, leading to a considerable number of redundant computations. Unlike BERT, Sentence-BERT maps sentences into a fixed-sized vector space, enabling the model to directly compare vectors for multiple sentences simultaneously. As a result, SBERT reduces the time complexity from quadratic to linear, leading to a significant speed-up in semantic comparison tasks.
Another critical improvement is Sentence-BERT's effectiveness in identifying semantic similarities. Because SBERT is specifically trained for STS tasks, it far surpasses native BERT in detecting related topics. To accomplish this, SBERT uses a Siamese or triplet network structure, which enables it to understand the semantic content of sentences better. The model generates sentence embeddings by considering the contextual relationships of words within pairs of sentences instead of one sentence at a time. It enhances the algorithm's ability to measure the semantic closeness between sentences accurately.
Furthermore, SBERT provides a much-needed solution for cross-lingual tasks as it can be trained on multilingual corpora. This is highly pertinent for SEO purposes as the internet is a global platform comprised of different languages. SBERT can generate sentence embeddings independently of the input language, allowing it to measure semantic textual similarity across languages.
Finally, Sentence-BERT offers a wider scope for transfer learning. The sentence embeddings generated from this model can be used for a variety of downstream tasks, including text classification, information extraction, sentiment analysis, and cluster analysis. These applications are relevant in SEO contexts to understand users' behaviors, preferences, and feedback, helping to optimize content for better visibility and ranking.
However, it's important to note that while SBERT undoubtedly offers considerable enhancements over BERT and is a valuable tool for practitioners in SEO, NLP and beyond, it is not a one-size-fits-all solution. Its usefulness might diminish in certain scenarios, such as when fine-grained understanding is required at the token level rather than the sentence level.
Which Applications Can Best Benefit from Implementing Sentence-BERT?
Whether you're managing an e-commerce site, a cutting-edge news agency, or the latest social media platform, harnessing the power of advanced language processing technology like Sentence-BERT (SBERT) can significantly benefit your application and its SEO performance.
SBERT is a modification of the widely used BERT language model developed by Google. Unlike its precursor, SBERT is trained to comprehend the context of complete sentences, vastly improving the semantic understanding of content. In terms of SEO, this type of algorithm can potentially provide better search results, by understanding the overall context rather than focusing solely on exact keyword matches.
First on the list of applications that would greatly benefit from SBERT are e-commerce platforms. These sites typically contain countless product descriptions and customer reviews that need to be effectively interpreted and categorized for successful SEO. SBERT could aid in refining product recommendations based on semantic similarity, making search results more accurate and contributing to an enhanced user experience. Better product visibility through accurate search results can lead to improved organic ranking, ultimately driving more traffic to the site.
Secondly, news websites stand to reap tremendous benefits from leveraging SBERT's power. By better understanding the content and context of news articles, these applications can ensure that stories are properly categorized and indexed for search engines. This can drive more relevant organic traffic to the site and can aid in increasing both user engagement and time spent on the site.
Third, social media and forum platforms can utilize SBERT for content moderation and sentiment analysis. By parsing the user-generated content, SBERT can help detect negative sentiment, cyberbullying, or spam, promoting a healthier user environment and boosting SEO indirectly by augmenting user experience.
Another beneficiary is the legal-tech sector which deals with a plethora of complex documents. SBERT can help in automated document analysis and knowledge extraction, making the search process more efficient for users and effectively improving the site's SEO.
Online learning platforms too can optimize their content using SBERT. Automating the process of tagging, categorizing, and recommending educational resources based on their full semantic context can provide a better user experience and improve site visibility.
In the world of customer support, using SBERT can enhance sorting and processing customer requests or complaints, aiding in greater customer satisfaction and higher organic search engine rankings.
Finally, SBERT could be a game-changer for digital healthcare portals. By improving the analysis and categorization of medical articles, forum discussions, or Q&As, users and patients can more easily and accurately locate needed medical information.
How Does Sentence-BERT Enhance SEO Strategies?
Search engine optimization (SEO) involves crafting website content in ways that make it more attractive to search engines, thereby enhancing website visibility, driving organic traffic, and improving rankings. To achieve this, it's necessary to understand the principles and technologies that search engines use to index and rank content, including advanced natural language processing (NLP) algorithms. In this context, Sentence-BERT, a powerful NLP tool developed by Google, enhances SEO strategies by decoding semantic content, thereby boosting search relevancy and page rankings.
Belonging to the transformer-based machine learning models, Sentence-BERT (SBERT) is an improvement on BERT (Bidirectional Encoder Representations from Transformers). While BERT processes sentences word by word, SBERT takes full sentences into account, providing a more comprehensive understanding of the text semantics. This enables search engines to better interpret and categorize content, facilitating in-depth content indexing and more precise search results.
The application of SBERT in SEO offers a competitive edge as it goes a step ahead in content comprehension. It has the potential to comprehend the entire context of content, and not just individual keywords, which is critical for content marketers. The shift away from a keyword-focused to a more intent-focused SEO model necessitates that search engines understand the overall context of the search query. SBERT's ability to understand sentence pairs allows it to better decipher the relationship and semantics between them. As a result, search engines become better equipped at matching user searches with the most relevant content, wherein the value added by SBERT can significantly improve search engine rankings.
Additionally, SBERT enhances SEO by facilitating faster, more effective content optimization. By using SBERT, content can be optimized at sentence level, giving search engines a better understanding of the true value and relevancy of the content. This assists in improving the web page rankings for targeted search phrases and improving content relevance for users, thus promoting increased user engagement and site longevity.
Moreover, SBERT can measure the semantic similarity between sentences, which can in turn be used to evaluate the quality of the content based on originality and uniqueness. This not only deters black-hat SEO tactics like keyword stuffing and content duplication, but also supports white-hat SEO strategies such as creating high-quality, relevant, and unique content.
Finally, SBERT contributes to enhancing SEO through a comprehensive understanding of user intent. With SBERT's deeper comprehension of sentence-level context, it can interpret the underlying intent behind a user's search query more precisely. This allows a search engine to provide more relevant and useful results, further improving user satisfaction and boosting SEO ranking over time.
What Challenges and Limitations Might One Encounter with Sentence-BERT?
The introduction of Sentence-BERT (SBERT) represented a significant advancement in the field of Natural Language Processing (NLP). By enabling semantic comparisons of sentences, this groundbreaking approach opened up new avenues in systems like search engines, chatbots, and recommendation systems. Although the efficacy of SBERT is remarkable, users may encounter a variety of challenges and limitations tied to SEO.
One of the foremost hindrances involves computational costs. SBERT is an extremely resource-intensive model that requires substantial computational power for training and inference. This could result in affordability issues for startups or smaller enterprises that do not possess the necessary resources and could also lead to scalability problems. The resource-intensive nature of SBERT may also lead to slower website loading times, which is a major concern for SEO.
Next, SBERT generates fixed-length embeddings irrespective of the sentence’s length. Sentence structure and the correlation between words, which are key components in comprehending text, might be ignored as the focus is on the whole sentence. This is a limitation since this may disregard the context within which specific keywords are used, making it less effective for SEO keyword strategy.
Moreover, SBERT's reliance on existing, pre-trained models can pose limitations. While it may work impressively with languages that have extensive, pre-trained models like English, its effectiveness might falter with low-resource languages. This limitation lowers its viability for global SEO strategies where multiple languages must be considered.
Furthermore, SBERT operates on a sentence level and might not be the most efficient for understanding short and precise queries or long and complex documents. The former is a bane in SEO because search queries are typically short phrases or single sentences. For longer text, SBERT struggles to maintain context over larger documents, thus reducing its effectiveness in scenarios where a deep comprehension of complete documents is necessary.
Another challenge lies in the realm of dynamic content updating. With the constant addition of new content, SBERT models would require frequent and resource-intensive retraining to keep the embeddings updated. In SEO context, reindexing and continuous updates play a pivotal role, and this requirement could drain resources and increase the complexity of maintaining the system.
Finally, SBERT might struggle with polysemous words - words that have multiple meanings depending upon the context. Consider the term "apple," it could mean a tech company or a fruit depending on the circumstance. Since SBERT operates on a sentence level, it may not always be evident which meaning would be the most appropriate one in SEO perspective.
Why is Sentence-BERT Preferred for Building SEO-Friendly Content?
Search Engine Optimization (SEO) is vital for increasing the visibility and traffic of a website. The advent of more practical and precise Natural Language Processing (NLP) models, like Sentence-BERT, has revolutionized SEO content creation. Despite other models available for semantic similarity search, Sentence-BERT is preferred for creating SEO-friendly content due to its unique features and remarkable efficiency.
To understand why Sentence-BERT is favored, we must first comprehend its functionality. Sentence-BERT, also known as SBERT, is a modification of the pre-trained BERT network that generates sentence embeddings significantly faster than the conventional BERT. This model facilitates real-time semantic searches over large text data, thus making it an excellent tool for content creators aiming to improve their SEO.
An essential part of SEO is understanding and matching the intent behind users’ queries with relevant content. The standard BERT requires comparisons of each sentence pair, which can be computationally demanding and slow, especially for long lists of sentences. However, Sentence-BERT resolves this inefficiency. It employs siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This structure ensures accurate and quick matches between user queries and your web content, improving SEO performance.
Unlike traditional methods that operate on keywords alone, Sentence-BERT understands the context behind sentences. It uses advanced NLP to comprehend the semantics and sentiment of sentences, providing an edge over traditional methods that lack context sensitivity. By understanding the meaning behind words in content, Sentence-BERT can better match keyword queries, even if they are phrased differently, thereby widening your webpage’s visibility.
Furthermore, Sentence-BERT factors in long-tail keywords - specific, less common keywords that collectively make up the majority of search-driven traffic. As these keywords are not as competitive, framing content around them using Sentence-BERT can prove beneficial for a website's ranking. This model’s intrinsic ability to capture the essence of sentences makes it efficient in identifying and ranking for these long-tail keywords.
In terms of language proficiency, Sentence-BERT supports over a hundred languages. This multi-language support enhances the range of your online content and makes your website accessible and SEO-friendly on an international scale. This feature is particularly useful for businesses wishing to improve their SEO in multiple language markets.
Lastly, Sentence-BERT creates concise and coherent sentence embeddings. This makes your website content more understandable and relevant for both search engines and users. Websites with highly relevant and engaging content could be promoted by search engines via higher page ranking, further improving overall SEO.
Can Sentence-BERT Help in Fixing SEO Penalties?
Search engine optimization (SEO) is an incredibly dynamic field, with Google algorithm changes and penalties forever shifting the landscape. SEO professionals are always on the lookout for new methods to mitigate penalties and rank higher. An emerging solution is Sentence-BERT (SBERT), a modification of the pre-trained BERT model, devised to derive semantic representations for sentences. Let's delve into whether or not SBERT can be beneficial in reducing SEO penalties.
SBERT can potentially offer three significant SEO benefits: improved understanding of semantic search intent, superior content optimization, and better link building strategy.
The first area where SBERT can help is the understanding of semantic search intent. One of the main reasons for SEO penalties is content that is not fully aligned with user intent. As search engines grow more sophisticated, they’re better equipped to understand the topical relevance and contextual meaning of search phrases. SBERT, by embedding context and semantics into its structure, can emulate this evolution. By better modeling complex, multi-sentence queries and responses, SBERT could help SEOs better understand user intent and optimize content accordingly.
Next, we turn to content optimization. Keyword stuffing, once a common practice, is now penalized by search engines. Writing content that aligns semantically with a topic is now the goal. In this context, SBERT’s capability to grasp the contextual and semantic identity of sentences is invaluable. By using SBERT, SEO professionals can ensure the content they write or modify is semantically aligned with the topic, ultimately helping to avoid penalties associated with keyword stuffing or irrelevant content.
Last but not least, SBERT can also assist with link-building strategies. Low-quality or irrelevant backlinks can also attract SEO penalties. An understanding of the semantic similarity between pages (as facilitated by SBERT) can help SEOs build or maintain a high-quality, relevant backlink profile. SEOs can avoid associating their site with semantically discordant or low-quality sources, substantially minimizing the risk of penalties.
However, it's worth noting that while SBERT may show substantial promise, it is not a silver bullet. It forms only one part of a multifaceted SEO strategy that must also include technical optimization, user experience enhancements, and ongoing content development. Also, the practicalities of integrating machine learning approaches like SBERT in an SEO strategy can be daunting, potential benefits notwithstanding.
Furthermore, Google is yet to definitively verify that it uses BERT or its derivatives in penalties. The search engine keeps its algorithm workings notably vague and SEOs can only make educated guesses. Therefore, while SBERT might form an interesting avenue for future SEO tactics, its current definitive role in avoiding penalties remains unclear.
How to Implement Sentence-BERT for Better Content Ranking?
Understanding and implementing Sentence-BERT for enhanced content ranking is crucial in the context of SEO. It is a brilliant approach to advance your content's findability and visibility, thus optimizing your website's organic search engine rankings. Sentence-BERT, also known as SBERT, is a modification of the pre-trained BERT model, which has been specifically tuned to compute semantically meaningful sentence embeddings. Let's explore how to implement Sentence-BERT for better content ranking.
Before proceeding with implementation, understanding the fundamental working of SBERT is important. The main difference between the original BERT model and SBERT is that BERT generates different embeddings for the same sentence in different contexts, while SBERT generates a fixed sentence vector. This property of SBERT is incredibly useful for semantic searches, where the objective is to find relevant content or similar content.
Firstly, consider the prerequisite of having Python, PyTorch, and the transformers library installed in your system. Once these are ready, you can use the following Python code to load the Sentence-BERT model:
from sentence_transformers import SentenceTransformer
sbert_model = SentenceTransformer('bert-base-nlp-mean-tokens')
To compute sentence embeddings, pass your sentences as a list to the encode() function:
sentence_embeddings = sbert_model.encode(sentences)
Once the model has provided the embeddings, these can be used to improve the content ranking of your website or application. These embeddings capture the semantic meaning of your content, which can be leveraged for various SEO applications.
Here is where the actual implementation of SBERT comes into play for SEO. For a standard search engine, when a user enters a query, it's usually matched against an index of keywords present in your content. However, semantic search aims to understand the searcher's intent and the contextual meaning of the query. The sentence embeddings from SBERT can be used to compare the semantic similarity between the search query and your content.
To rank your content, compute the cosine similarity between the query embedding and all the sentence embeddings of your content.
The Python library 'Scikit-learn' provides an easy way to compute cosine similarity.
from sklearn.metrics.pairwise import cosine_similarity
query_embedding = sbert_model.encode([user_query])
cosine_similarities = cosine_similarity(query_embedding, sentence_embeddings)
After calculating the cosine similarities, sort your content based on these similarity scores. This approach will rank your content not merely on keyword matching, but on semantic similarity to the user's query. Hence, SBERT provides a more intelligent approach to satisfying user intent and delivering highly relevant content, which ultimately improves SEO rankings.
Remember, search engines like Google have moved beyond simple keyword matching. They're focusing more on the context and semantics of user queries. By leveraging Sentence-BERT in your content ranking algorithm, you're not only staying competitive in the SEO landscape but also enhancing user experience by delivering more relevant and contextually accurate content.
What is the Impact of Sentence-BERT on Future SEO Practices?
Sentence-BERT (SBERT), derived from the BERT (Bidirectional Encoder Representations from Transformers) model, is a modification that enables the generation of semantic sentence-level embeddings efficiently. This innovation delivers more precision and speed when drawing out semantic similarities among sentences, which has consequential implications on the future of Search Engine Optimization (SEO) practices.
The effectiveness of SEO endeavors depends on better understanding content, focusing on how search engines perceive site relevancy and usefulness. Google and other major search engines use AI and machine learning to generate almost human-like comprehension of webpages. The introduction of Sentence-BERT, therefore, brings SEO a step closer to semantic search optimization due to its superior grasp of linguistic nuance.
Search engines equipped with SBERT can measure the genuine contextual relevance of content beyond single words or phrases. This attribute allows them to gauge the whole context of a sentence and draw comprehensive, meaningful correlations with user queries. SEO practitioners must, as a result, prioritize coherence and context in their keyword usage as opposed to singular keyword focusing.
Incorporation of SBERT into larger systems like Google's Multitask Unified Model (MUM) will lead to increased emphasis on high-quality, user-centric content. As the algorithm evolves, superficial keyword stuffing becomes less effective. Instead, content that truly answers user queries while considering semantic associations will rank better. This progression means that content producers will have to pay closer attention to the semantic relations between words and use keywords that fit the overall context.
Additionally, the advent of Sentence-BERT can have a significant impact on voice search optimization. The model’s capability to understand context better means it can handle informal, conversation-like queries typical of voice searches proficiently. Consequently, SEO practitioners may need to adapt their strategies to cater for the increased use of long-tail keywords and natural language structures in voice searches.
In terms of link building, SBERT’s ability to generate efficient sentence embeddings could lead to more accurate evaluations of external sites’ relevance. By comparing the sentence embeddings on both pages, search engines can determine the relevance and quality of outbound and inbound links more effectively.
A significant facet of the SEO world that SBERT could impact is multilingual SEO. SBERT has multilingual models capable of understanding and comparing sentences across different languages. This feature can revolutionize international SEO as search engines will be better equipped to analyze and compare content across multiple languages.
How Market Brew Models Sentence-BERT Using Embeddings and Cosine Similarities
To create comprehensive content analysis and prediction, Market Brew utilizes Sentence-BERT, an innovative technique involving embeddings and cosine similarities. In essence, Sentence-BERT uses a model named BERT (Bidirectional Encoder Representations from Transformers) that is designed to understand the context of every word in a sentence.
Sentence-BERT utilizes vectors, a mathematical depiction that assigns each word a unique identifier, based on its contextual significance. These word vectors, often referred to as embeddings, retain semantic meaning, allowing equivalence search and sorting of relevant phrases.
Market Brew's A/B testing platform takes these Sentence-BERT embeddings and cosine similarity to build a model around Google's AI Overviews. Cosine similarity is a measure that calculates the cosine of the angle between two vectors. This measure gives an indication of how similar two pieces of content are.
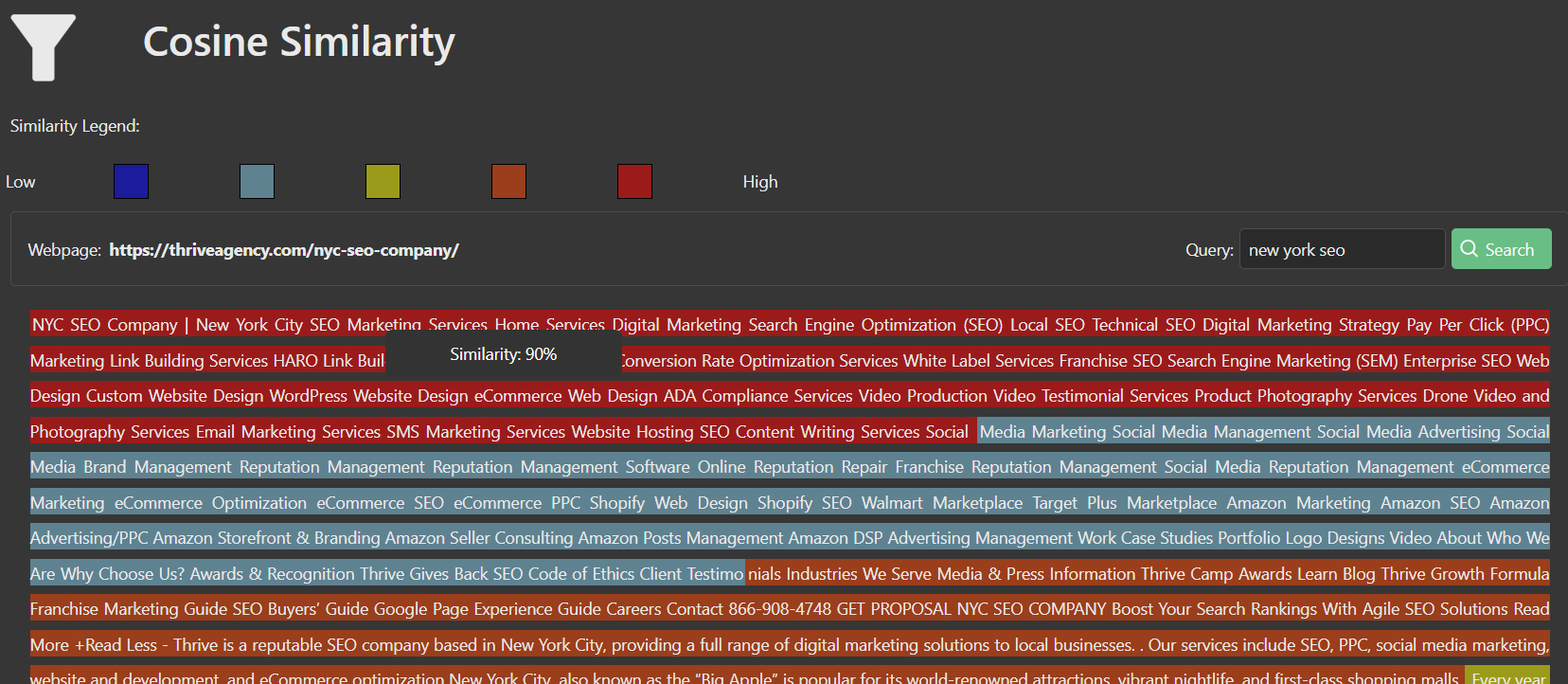
On its own, the cosine similarity module enables users to visualize embedding chunks on the page, and find out how similar their chunks of content are to different queries. The blended similarity module allows users to understand how targeted their content is on a page by visualizing the average cosine similarities across all embedding chunks.
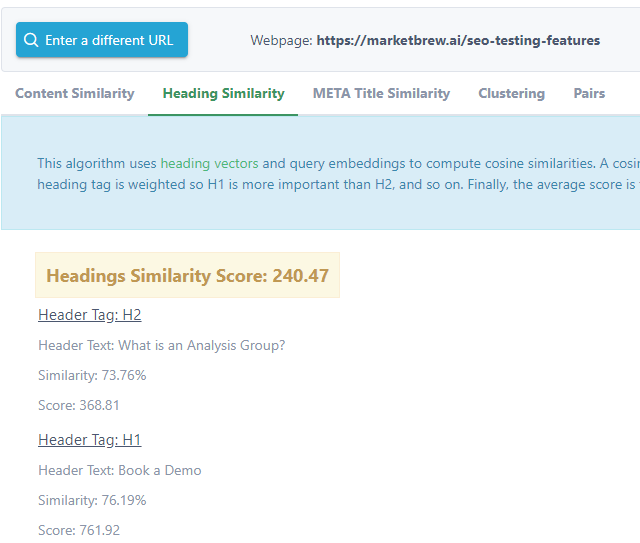
In addition, Market Brew extends its SEO capabilities through Heading Vector Similarity and META Title Similarity. This functionality lets users see how Google, as a representative search engine, perceives their headings and META Title in terms of embeddings. Essentially, this gives website owners insights into how their website's categorical structure appeals to search engines.
Furthermore, Market Brew also provides tools such as K-Means embedding clusters and Pairwise embedding clusters. These help users comprehend the semantic structure of their content. They can identify the cluster where the main content fits into or discover which parts of the page are deemed similar by Google.
In terms of SEO, Market Brew's Sentence-BERT model and its associated tools provide an advanced understanding of how website content relates to search queries. By tuning page content to maximize cosine similarity where required, website owners can effectively increase the relevance of their content to targeted search queries. This leads to improved search engine ranking, more organic traffic, and in turn, higher business performance.
Market Brew models Sentence-BERT using embeddings and cosine similarities in its groundbreaking AI Overviews Tool, creating an effective solution to measure and improve the relevance of website content in the context of SEO. This innovative model supports comprehensive content analysis and prediction, allowing businesses to effectively target and optimize their content for better visibility and performance in search engines.
Ready to Take Control of Your SEO?
See how Market Brew's predictive SEO models and expert team can unlock new opportunities for your site. Get tailored insights on how we can help your business rise above the competition.
Schedule a demonstration today via our Menu Button and Contact Form to discover how we engineer SEO success.
You May Also Like:
Guides & Videos
Topic Clusters: How to Improve Your Search Engine Rankings
Guides & Videos
Complete Guide to Product Listing Optimization
News
Google Says… Market Brew Sees
From ambiguity to actionable insight.
Decode ranking systems, surface leverage points, and deploy with clarity.